
سيطرت Large Language Models بشكل واسع على مشهد الـ AI في عام ٢٠٢٣ ابتداءً من ظهور ChatGPT في أواخر عام ٢٠٢٢ الذي حطّم رقم تبنّي التقنية بأسرع قاعدة مستخدمين نموّاً.
الـ Large Language Models هي مجموعة فرعية من الـ Generative AI الذي يشير إلى أنظمة قادرة على توليد محتوى، كما يوحي الاسم بوضوح، بصيغ مختلفة: جدولية ونصية وصور …إلخ. تُدرَّب الـ LLMs على كميات كبيرة من البيانات النصية مما يجعلها فعّالة جداً في توليد إجابات شبيهة بإجابات البشر.
في هذا المقال، سأناقش تعريف الـ LLMs وتطوّرها وتطبيقاتها مع تركيز خاص على المفاهيم الرئيسية بدءاً من Pre-training وfine-tuning ووصولاً إلى prompt engineering.
الملخّص كالتالي:
- LLMs
- Pre-training
- Fine-tuning
- Prompt engineering
- التطبيقات
LLMs
الـ LLMs هي نماذج deep learning تُدرَّب على كميات هائلة من البيانات النصية (٣٠٠ مليار كلمة ~ ٥٧٠ GB لـ ChatGPT) مأخوذة من الإنترنت، مما يسمح لها بالتقاط أنماط ضخمة داخل اللغات والتفوّق على جميع التقنيات والنماذج القائمة في التنبّؤ بالكلمة التالية.
تطوّرت نماذج اللغة بشكل كبير خلال السنوات الخمس الماضية عبر معماريات مختلفة كما يوضّح الرسم أدناه:
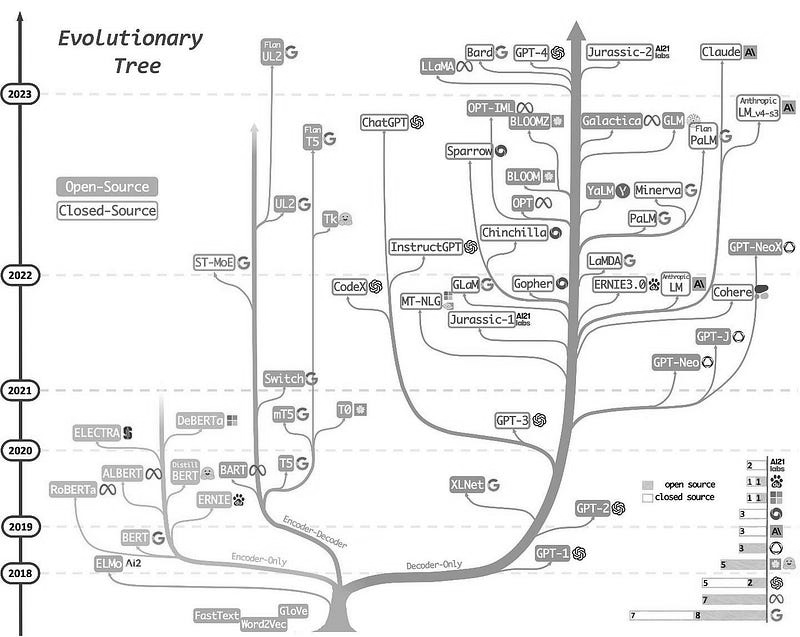
حيث:
- Encoders: تحوّل تسلسلاً من الكلمات إلى تسلسل من الأرقام (embeddings)
- Encoder-decoders: تأخذ نصاً كمدخل وتولّد تسلسلاً جديداً من الكلمات كمخرج (الترجمة مثلاً)
- Decoders: تولّد نصاً كمخرج انطلاقاً من سياق
تحظى هذه النماذج الأخيرة، الـ decoders، باهتمام كبير منذ عام ٢٠٢٠ بفضل معماريتها Transformers architecture التي فتحت أداءً غير مسبوق من خلال unsupervised learning ضخم وكميات كبيرة من البيانات النصية وطبقات عميقة (GPT-1، ١١٧ مليون معامل). تشير المعاملات إلى weights وbiases التي تتعلّمها الـ neural network.
وبناءً على ذلك، خلال التدريب، تتمكّن الـ LLMs من تعلّم قدرتين رئيسيتين:
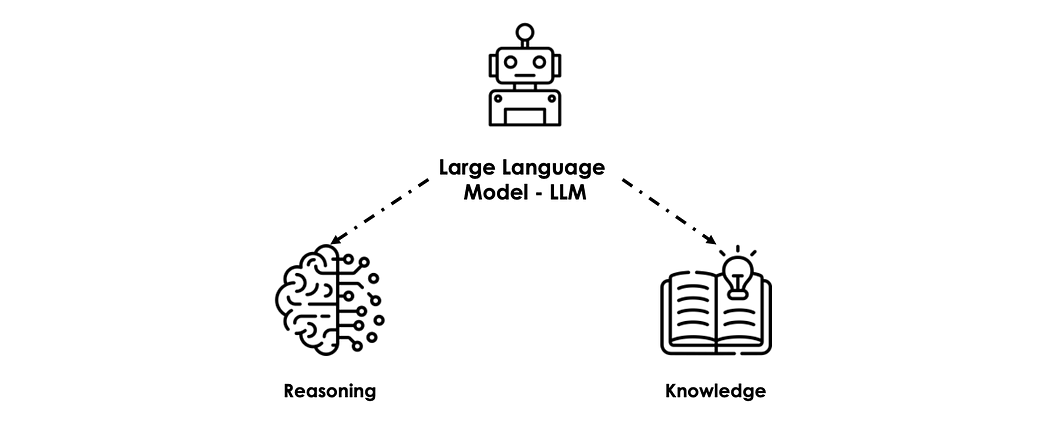
- المعرفة: تأتي من كل المعلومات والبيانات التي دُرّب عليها. على سبيل المثال، يمتلك ChatGPT 3.5 قاعدة معرفة مأخوذة من جميع أنحاء الإنترنت حتى يناير ٢٠٢٢.

- الاستدلال: مُلتقَط من الأنماط المختلفة داخل البيانات. ويصبح الـ LLM قادراً على تنفيذ مهامّ بشرية كلاسيكية مثل استخراج المعلومات/الرؤى وحلّ المشكلات …إلخ.
تُظهر الـ LLMs المدرَّبة على مجموعات بيانات كبيرة من الكود (Github) قدرات استدلال أفضل، وهي بديهياً أنماط ومنطق مكتسَب من لغات البرمجة.
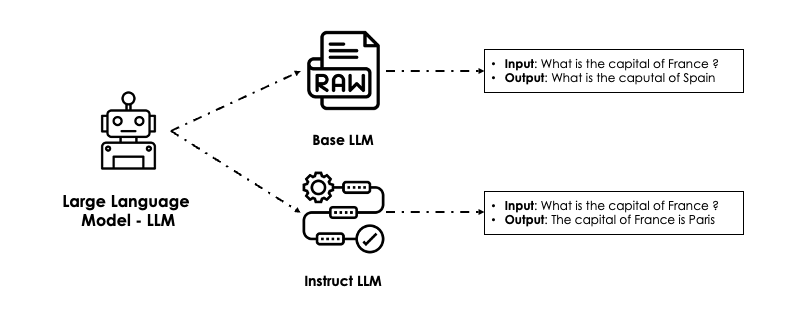
يمكن أيضاً تصنيفها إلى نوعين من الـ LLMs:
- Base LLM: النسخة "الخام" من النموذج التي تُستخدم للتنبّؤ بالكلمة التالية. ويُحصل عليها عبر pre-training لنموذج الـ deep learning (انظر قسم Pre-training أدناه).
على سبيل المثال، إذا طرحت سؤال "What is the capital of France?"، فسيُخرج الـ LLM على الأرجح: "What is the capital of Spain?"
GPT3 هو base large language model. - Instruct LLM: نسخة fine-tuned (انظر قسم Fine-tuning أدناه) مدرَّبة عادةً على dataset من الأسئلة والأجوبة وتُستخدم بشكل رئيسي لمهامّ الدردشة. على سبيل المثال، ChatGPT هو نسخة Instruct من GPT3.
في هذه الحالة، وبالنظر إلى السؤال ذاته، سيُرجع الـ LLM: "The capital of France is Paris".
كما ذُكر أعلاه، تُدرَّب الـ LLMs للتنبّؤ بالكلمة التالية، وهذا قد يجعلها افتراضياً عرضةً للـ hallucination، حيث يكون المحتوى المولَّد سليماً نحوياً ودلالياً ولكنّه لا يعكس واقعاً حقيقياً.
إنّها مفاضلة بين الموضوعية والإبداع تتحكّم فيها hyperparameter تُسمّى temperature. ويمكن أن تكون الـ hallucination مشكلة خطيرة لأنّها تنشر معلومات خاطئة وقد يكون لها عواقب وخيمة بحسب استخدام الـ LLM.
Pre-training
الـ Pre-training هو المهمّة الأولية لتدريب نموذج الـ deep learning على كميات هائلة من البيانات النصية المأخوذة في معظم الحالات من الإنترنت. يتعلّم النموذج بنية اللغة وقواعدها والحسّ السليم المضمَّن داخل اللغة. وهذه هي خطوة التعلّم الأولى لمعمارية الـ deep learning. ومن الحاسم تنظيف بيانات التدريب بدقّة لمنع النموذج من تعلّم معلومات منحازة.
تجدر الإشارة أيضاً إلى أنّ تدريب Large Language Model يستهلك وقتاً وموارد ومالاً كثيراً. ومع عدم وجود بيانات رسمية، يُقدَّر أنّ GPT-4 دُرّب على ٥٧٠GB من البيانات باستخدام ٢٥٫٠٠٠ Nvidia A100 GPUs لمدّة ١٠٠ يوم تقريباً.
نظراً لتوزّع المواضيع والمجالات داخل بيانات الإنترنت الإجمالية، فسيؤدّي الـ LLM على الأرجح أداءً جيداً على اللغة العامة وسيواجه صعوبة مع المهامّ المتخصّصة بمجال معيّن.
Fine-tuning
الـ Fine-tuning هو مهمّة مواصلة تدريب النموذج من أجل تعزيز المعرفة أو الاستدلال أو كليهما. وهو مفيد عند التعامل مع مهامّ إما:
- مفردة: مثل Q&A والتلخيص …
- متخصّصة بمفردات معيّنة: طبّية ومالية …إلخ
مثلاً، تمّ الحصول على ChatGPT عبر fine-tuning لـ GPT3 base LLM.
يُنظَّم dataset الخاصّ بالـ fine-tuning عادةً في صيغتين رئيسيتين:
- البنية الأولى: (Instruction، Input، Output) التي تعزّز قدرات الاستدلال لدى الـ LLM بداهةً.
- البنية الثانية: (Input، Output) التي توسّع معرفته
إنّها عملية تكرارية توفّر أداءً أعلى لأنّها تزيد من تماسك النموذج وموثوقيّته وتقلّل من الـ hallucination. كما أنّها أقلّ تكلفة بكثير من التدريب وتسمح بمزيد من التحكّم والشفافية في المعرفة الجديدة.
Prompt Engineering
تعمل الـ Prompts كمدخلات تُقدَّم إلى Language Model (LLM) لتحسين جودة المخرج المولَّد. ويُعدّ توظيف الـ prompts منهجاً استراتيجياً لتقديم مشكلة إلى الـ LLM وتوجيه عملية تأمّله واستدلاله للحصول على نتائج مثلى ودقيقة. وتُعرف تقنية صياغة الـ prompts بـ prompt engineering.
قد يكون للـ prompt البنية التالية:

حيث:
- Context: هو بيانات نصية اختيارية يمكن استخراج المعلومات منها، ويُستخدم أيضاً لتحديد نبرة ودور الـ agent للـ LLM.
- Question: هو الاستعلام الذي يحتاج إلى إجابة.
- Instructions: وهي الخطوات التي يجب على الـ LLM اتّباعها للإجابة عن السؤال، وتُستخدم أيضاً لتحديد صيغة المخرج وطوله …إلخ.
فيما يلي بعض مبادئ الـ prompting:
- تعليمات واضحة
- التحقّق ممّا إذا كانت الشروط مستوفاة
- استخدام delimiters
- تنسيق المخرج بصيغة منظَّمة (JSON، Markdown، …)
- Few-shots prompting: إعطاء عيّنة من tuples من (inputs، output) واستعلام input جديد - عملية التفكير
- تحديد الخطوات الواجب اتّباعها لمهمّة حلّ المشكلة
- توجيه النموذج لإيجاد حلّه الخاصّ قبل التسرّع إلى استنتاج
يتضمّن الـ prompting عملية تكرارية نهدف فيها إلى توضيح التعليمات وصقلها لتحقيق نتائج محسَّنة. وهو جهد ديناميكي ومستمر لتعزيز التوجيه المُقدَّم إلى النظام للحصول على نتائج أكثر فعّالية.

ومن المثير للاهتمام ملاحظة أنّ الاختيار بين prompt engineering وfine-tuning والتدريب يعتمد بشكل أساسي على حالة الاستخدام المحدّدة ومتطلّباتها. وستزداد البيانات والموارد اللازمة بالتوازي مع الانتقال من مهمّة إلى أخرى.
التطبيقات
وجدت الـ LLMs تطبيقات في مجالات كثيرة بفضل قدرتها على توليد محتوى نصي بأسلوب شبيه جداً بأسلوب البشر. ويُلخّص الرسم البياني أدناه بعضاً من أشهر استخدامات الـ LLMs:
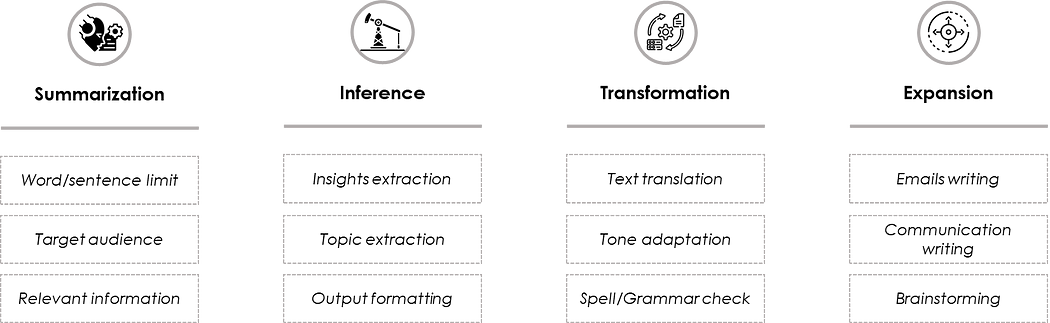
- التلخيص: هو مهمّة تقليص حجم المدخل النصي، ويمكن أن يكون مبنياً إما على حدّ كلمات أو معلومات مستهدفة أو لجمهور معيّن.
- الاستدلال: يشير إلى مهمّة استخراج الرؤى من النص مع خيار تحديد صيغة المخرج.
- التحويل: يستطيع تحديث/إعادة كتابة المدخل أو حتى ترجمته
- التوسعة: هي من أكثر الميزات إثارة للاهتمام في مكاسب الإنتاجية عند استخدام الـ LLMs، إذ تتيح توليد رسائل البريد الإلكتروني والاتّصالات وحتى الأفكار لجلسات العصف الذهني
تستعرض هذه التطبيقات الإمكانات العالية للـ LLMs وتُسقط الأثر الذي يمكن أن تحدثه على المستوى التقني عند التعامل مع مهامّ الـ NLP، وهو ما قد ينعكس أيضاً على مستوى العمل بفضل الميزات والإمكانات الجديدة والمهمّة التي تفتحها.
الخاتمة
تُشكّل الـ Large Language Models (LLMs) نموذجاً جديداً في مقاربتنا لمهامّ الـ NLP وتُظهر مرونة ودقّة غير مسبوقتين. ويتميّز هذا المجال الديناميكي ببحث وتطوير مستمرّين، مع ظهور LLMs جديدة باستمرار وتصنيفها على أساس أسبوعي تقريباً.
سيكون عام ٢٠٢٤ في الغالب عام الـ LLMs الصغيرة/النانوية التي تعمل على أجهزة صغيرة وتتخصّص في مهامّ محدّدة. تُعدّ Phi-2 وThe Rabbit R1 علامات واعدة على توجّه هذا العام، وأنا شخصياً متلهّف لما هو قادم!