
ملفّات PDF أو Portable Document Format هي نوع من الملفّات طوّرته Adobe من أجل تمكين إنشاء أشكال مختلفة من المحتوى. وعلى وجه الخصوص، تتيح أماناً متّسقاً فيما يتعلّق بتغيير المحتوى. ويمكن لملفّ PDF أن يستضيف أنواعاً مختلفة من البيانات: نصوص وصور ووسائط …إلخ. وهو ملفّ منظَّم بـ tags مما يجعل تحليله سهلاً تماماً كصفحة HTML.
وبناءً على ذلك، ومن باب التنظيم، يمكننا فصل ملفّات PDF إلى فئتين:
- ملفّات مبنية على النص: تحتوي على نصّ يمكن نسخه ولصقه
- ملفّات مبنية على الصور: تحتوي على صور مثل المستندات الممسوحة
في هذا المقال، سنستعرض python libraries الرئيسية التي تتيح تحليل ملفّات PDF، سواء المبنيّة على النص أو المبنيّة على الصور التي ستخضع لـ OCR ثم تُعالج كملفّ مبنيّ على النصّ. وسنغطّي أيضاً في الفصل الأخير كيفية استخدام خوارزمية الكشف عن الأشياء YOLOV3 لتحليل الجداول.
الملخّص كالتالي:
- ملفّات pdf المبنيّة على الصور
1.1. OCRMYPDF - ملفّات pdf المبنيّة على النص
2.1. PyPDF2
2.2. PDF2IMG
2.4. Camelot
2.5. Camelot ممزوج بـ YOLOV3
من باب التوضيح طوال هذا المقال، سنستخدم ملفّ pdf هذا الرابط.
ملفّات pdf المبنيّة على الصور
1. OCRMYPDF
Ocrmypdf هي حزمة python تتيح تحويل ملفّ pdf مبنيّ على الصور إلى ملفّ مبنيّ على النص، حيث يمكن تحديد النص ونسخه ولصقه.
لتثبيت ocrmypdf يمكنك استخدام brew لـ macOS وLinux باستخدام سطر الأوامر:
brew install ocrmypdfبمجرّد تثبيت الحزمة، يمكنك تطبيق OCR على ملفّ pdf بتنفيذ سطر الأوامر التالي:
ocrmypdf input_file.pdf output_file.pdfحيث:
- ocrmypdf: متغيّر المسار
- input_file.pdf: ملفّ pdf المبنيّ على الصور
- output_file.pdf: ملفّ المخرج المبنيّ على النص
بمجرّد تحويل الـ pdf إلى ملفّ مبنيّ على النص، يمكن معالجته باستخدام جميع المكتبات المفصَّلة أدناه.
لمزيد من التفاصيل حول ocrmypdf، يُرجى زيارة الموقع الرسمي.
ملفّات pdf المبنيّة على النص
في هذا القسم، سنركّز بشكل رئيسي على ثلاث مكتبات python تتيح استخراج محتوى ملفّ pdf مبنيّ على النص.
1. PyPDF2
PyPDF2 هي أداة python تتيح لنا تحليل معلومات أساسية حول ملفّ pdf مثل المؤلف والعنوان …إلخ. كما تتيح الحصول على نصّ صفحة معيّنة إلى جانب تقسيم الصفحات وفتح الملفّات المشفَّرة بافتراض امتلاك كلمة المرور.
يمكن تثبيت PyPDF2 باستخدام pip بتنفيذ سطر الأوامر التالي:
pip install PyPDF2نُلخّص جميع الوظائف المذكورة أعلاه في النصوص البرمجية التالية بـ python:
- قراءة ملفّ pdf:
from PyPDF2 import PdfFileWriter, PdfFileReader
PDF_PATH = "boeing.pdf"
pdf_doc = PdfFileReader(open(PDF_PATH, "rb"))- استخراج معلومات المستند:
print("---------------PDF's info---------------")
print(pdf_doc.documentInfo)
print("PDF is encrypted: " + str(pdf_doc.isEncrypted))
print("---------------Number of pages---------------")
print(pdf_doc.numPages)
>> ---------------PDF's info---------------
>> {'/Producer': 'WebFilings', '/Title': '2019 12 Dec 31 8K Press Release Exhibit 99.1', '/CreationDate': 'D:202001281616'}
>> PDF is encrypted: False
>> ---------------Number of pages---------------
>> 14- تقسيم المستندات صفحة بصفحة:
#indexation starts at 0
pdf_page_1 = pdf_doc.getPage(0)
pdf_page_4 = pdf_doc.getPage(3)
print(pdf_page_1)
print(pdf_page_4)
>> {'/Type': '/Page', '/Parent': IndirectObject(1, 0), '/MediaBox': [0, 0, 612, 792], '/Resources': IndirectObject(2, 0), '/Rotate': 0, '/Contents': IndirectObject(4, 0)}
>> {'/Type': '/Page', '/Parent': IndirectObject(1, 0), '/MediaBox': [0, 0, 612, 792], '/Resources': IndirectObject(2, 0), '/Rotate': 0, '/Contents': IndirectObject(10, 0)}
- استخراج النص من صفحة:
text = pdf_page_1.extractText()
print(text[:500])
>> '1Boeing Reports Fourth-Quarter ResultsFourth Quarter 2019 Financial results continue to be significantly impacted by the 737 MAX grounding Revenue of $17.9 billion, GAAP loss per share of ($1.79) and core (non-GAAP)* loss per share of ($2.33) Full-Year 2019 Revenue of $76.6€billion, GAAP loss per share of ($1.12) and core (non-GAAP)* loss per share of ($3.47) Operating cash flow of ($2.4)€billion; cash and marketable securities of $10.0 billion Total backlog of $463 billion, including over 5,400'- دمج المستندات صفحة بصفحة:
new_pdf = PdfFileWriter()
new_pdf.addPage(pdf_page_1)
new_pdf.addPage(pdf_page_4)
new_pdf.write(open("new_pdf.pdf", "wb"))
print(new_pdf)
>> <PyPDF2.pdf.PdfFileWriter object at 0x11e23cb10>- اقتصاص الصفحات:
print("Upper Left: ", pdf_page_1.cropBox.getUpperLeft())
print("Lower Right: ", pdf_page_1.cropBox.getLowerRight())
x1, y1 = 0, 550
x2, y2 = 612, 320
cropped_page = pdf_page_1
cropped_page.cropBox.upperLeft = (x1, y1)
cropped_page.cropBox.lowerRight = (x2, y2)
cropped_pdf = PdfFileWriter()
cropped_pdf.addPage(cropped_page)
cropped_pdf.write(open("cropped.pdf", "wb"))
- تشفير وفكّ تشفير ملفّات PDF:
PASSWORD = "password_123"encrypted_pdf = PdfFileWriter()encrypted_pdf.addPage(pdf_page_1)encrypted_pdf.encrypt(PASSWORD)encrypted_pdf.write(open("encrypted_pdf.pdf", "wb"))read_encrypted_pdf = PdfFileReader(open("encrypted_pdf.pdf", "rb"))print(read_encrypted_pdf.isEncrypted)if read_encrypted_pdf.isEncrypted: read_encrypted_pdf.decrypt(PASSWORD)print(read_encrypted_pdf.documentInfo)>> True>> {'/Producer': 'PyPDF2'}
لمزيد من المعلومات حول PyPDF2، يُرجى زيارة الموقع الرسمي.
2. PDF2IMG
PDF2IMG هي مكتبة python تتيح تحويل صفحات pdf إلى صور يمكن معالجتها، مثلاً، بواسطة خوارزميات الـ computer vision.
يمكن تثبيت PDF2IMG باستخدام pip بتنفيذ سطر الأوامر التالي:
pip install pdf2imageيمكننا تحديد الصفحة الأولى والصفحة الأخيرة ليتمّ تحويلها إلى صور من ملفّ الـ pdf.
from pdf2image import convert_from_path
import matplotlib.pyplot as plt
page=0
img_page = convert_from_path(PDF_PATH, first_page=page, last_page=page+1, output_folder="./", fmt="jpg")
print(img_page)
>> <PIL.PpmImagePlugin.PpmImageFile image mode=RGB size=1700x2200 at 0x11DF397D0>
3. Camelot
Camelot هي مكتبة python متخصّصة في تحليل جداول صفحات pdf. ويمكن تثبيتها باستخدام pip بتنفيذ سطر الأوامر التالي:
pip install camelot-py[cv]مخرج التحليل هو pandas dataframe وهو مفيد جداً لمعالجة البيانات.
import camelot
output_camelot = camelot.read_pdf(
filepath="output_ocr.pdf", pages=str(0), flavor="stream"
)
print(output_camelot)
table = output_camelot[0]
print(table)
print(table.parsing_report)
>> TableList n=1>
>> <Table shape=(18, 8)>
>> {'accuracy': 93.06, 'whitespace': 40.28, 'order': 1, 'page': 0}عندما تحتوي صفحة الـ pdf على نصّ، سيكون مخرج Camelot عبارة عن data frame يحتوي على النصّ في الأعمدة الأولى ثم الجدول المطلوب لاحقاً. ومع بعض المعالجة الأساسية يمكننا استخراجه كما يلي:
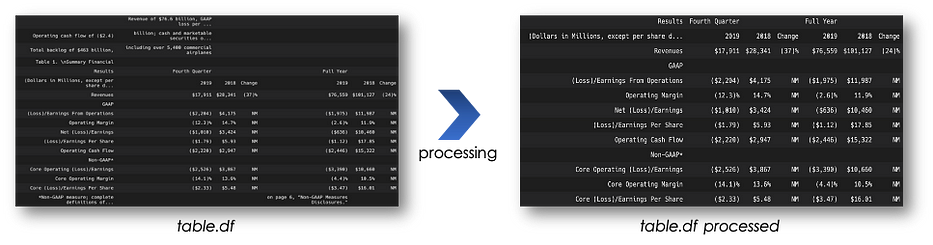
يقدّم Camelot نكهتين lattice وstream، وأنصح باستخدام stream لأنّه أكثر مرونة مع بنية الجداول.
4. Camelot ممزوج بـ YOLOV3
يقدّم Camelot خيار تحديد المناطق المراد معالجتها عبر المتغيّر table_areas="x1,y1,x2,y2" حيث (x1، y1) هي left-top و(x2، y2) هي right-bottom في فضاء إحداثيات PDF. وعند ملئها، تتحسّن نتيجة التحليل بشكل ملحوظ.
شرح الفكرة الأساسية
إحدى طرق أتمتة تحليل الجداول هي تدريب خوارزمية قادرة على إرجاع إحداثيات bounding boxes المحيطة بالجداول، كما هو مفصَّل في الـ pipeline التالي:

إذا كانت صفحة الـ pdf الأصلية مبنيّة على الصور، يمكننا استخدام ocrmypdf لتحويلها إلى مبنيّة على النص لكي نتمكّن من الحصول على النصّ داخل الجدول. ثم ننفّذ العمليات التالية:
- تحويل صفحة pdf إلى صورة باستخدام
pdf2img - استخدام خوارزمية مدرَّبة لكشف مناطق الجداول.
- تطبيع الـ bounding boxes باستخدام image dimension، مما يتيح الحصول على المناطق في فضاء pdf باستخدام pdf dimensions التي يتمّ الحصول عليها عبر
PyPDF2. - تغذية المناطق إلى
camelotوالحصول على pandas data-frames المقابلة.
عند كشف جدول في صورة pdf نقوم بتوسيع الـ bounding box من أجل ضمان تضمينه بالكامل، كما يلي:
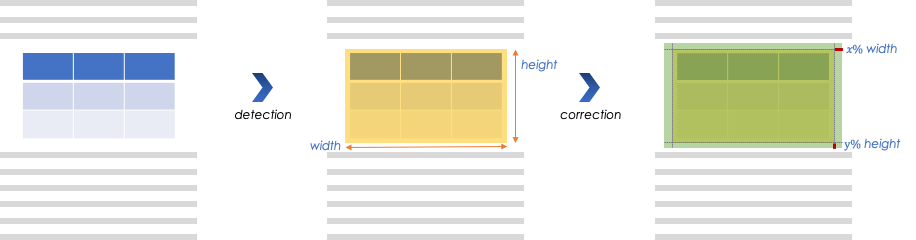
كشف الجداول
الخوارزمية التي تتيح كشف الجداول ليست سوى yolov3، وأنصحك بقراءة مقالي السابق حول كشف الأشياء.
نقوم بـ finetune للخوارزمية لكشف الجداول وإعادة تدريب المعمارية بأكملها. للقيام بذلك، ننفّذ الخطوات التالية:
- إنشاء قاعدة بيانات للتدريب باستخدام
Makesenseوهي أداة تتيح labeling والتصدير بصيغة YOLO:
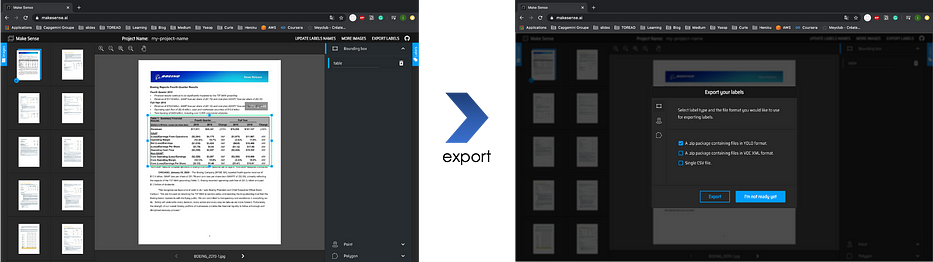
- تدريب
yolov3repositoryمعدَّل بما يناسب غرضنا على AWS EC2، نحصل على النتائج التالية:
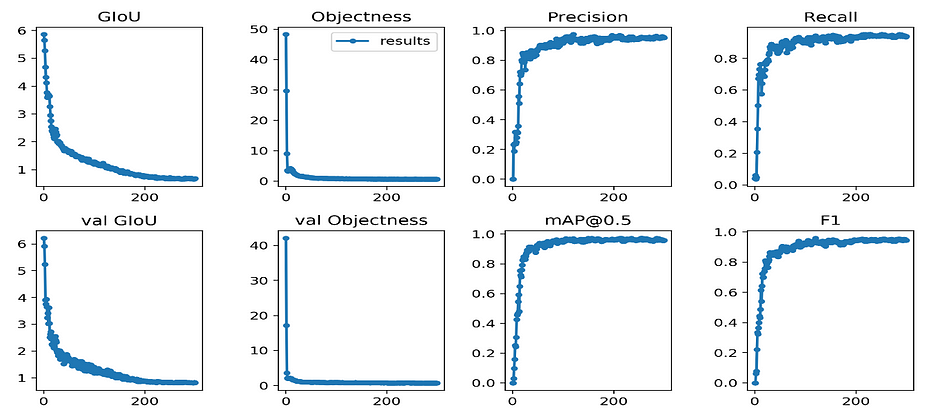
التوضيح
تبدو الاكتشافات كما يلي:

الخاتمة
عند مزج مكتبات python القياسية مع خوارزميات الـ deep learning، يمكن تعزيز تحليل مستندات PDF بشكل ملحوظ. والواقع أنّه، باتباع الخطوات ذاتها، يمكننا تدريب خوارزمية YOLOV3 لكشف any other object في صفحة pdf مثل الرسومات والصور التي يمكن استخراجها من صفحة الصورة.
يمكنك مراجعة مشروعي في GitHub.
لا تتردّد في الاطّلاع على مقالاتي السابقة التي تتناول:
- Deep Learning’s mathematics
- Convolutional Neural Networks’ mathematics
- Object detection & Face recognition algorithms
- Recurrent Neural Networks