
تُستخدم الشبكات العصبية الالتفافية (CNN) على نطاق واسع في معالجة المشكلات المرتبطة بالصور، مثل الكشف عن الأشياء/الحروف والتعرف على الوجوه. في هذا المقال، سنركّز على أشهر المعماريات بدءًا من LeNet وصولًا إلى الشبكات السيامية (Siamese networks)، وأغلبها يتّبع المعمارية التالية:
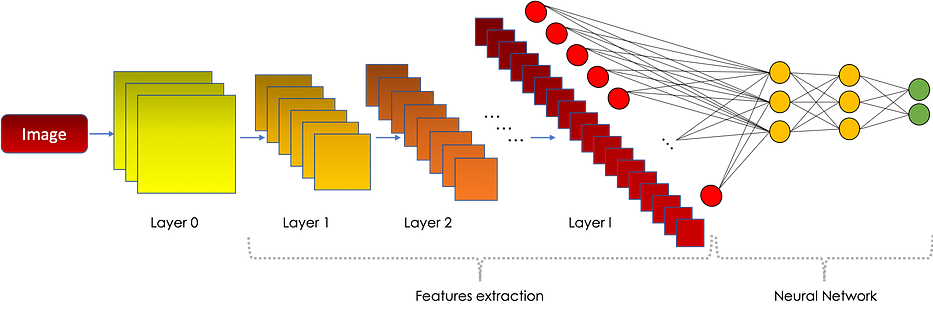
إذا لم تكن لديك أي معرفة بالشبكات العصبية الالتفافية، أنصحك بقراءة الجزء الأول من هذا المقال، الذي يناقش أساسيات CNNs.
ملاحظة: بما أن Medium لا يدعم LaTeX، فقد تم إدراج التعبيرات الرياضية كصور. لذا أنصحك بإيقاف الوضع الداكن للحصول على تجربة قراءة أفضل.
جدول المحتويات
- Cross-Entropy
- تصنيف الصور
- الكشف عن الأشياء, YOLOv3
- التعرف على الوجوه, Siamese Networks
Cross-Entropy
عند تصنيف صورة، غالبًا ما نستخدم دالّة softmax في الطبقة الأخيرة بحجم (C,1) حيث يمثّل C عدد الفئات المعنية.
السطر i من المتجه هو احتمال أن تنتمي صورة الإدخال إلى الفئة i. تُحدَّد predicted class لتكون تلك المقابلة لـ highest probability.
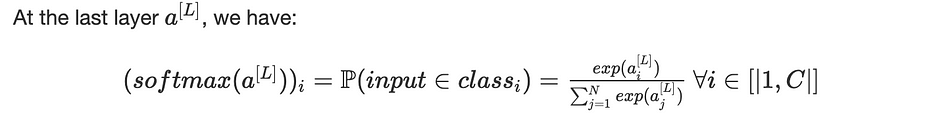
تتعلّم الشبكة باستخدام backpropagation وتحسّن دالّة cross entropy المعرّفة على النحو التالي:
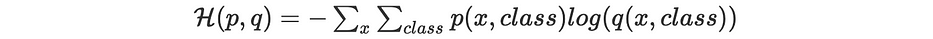
حيث:
- p(x,class) هي الاحتمالية المرجعية وتساوي 1 إذا كان الكائن ينتمي فعلًا إلى الفئة المُدخَلة و0 خلاف ذلك
- q(x,class) هي الاحتمالية، التي تتعلّمها الشبكة من خلال softmax، بأن الكائن x ينتمي إلى تلك الفئة
بالنسبة لإدخال x∈class_j:
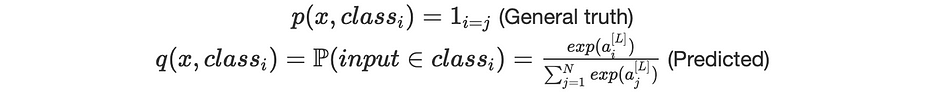
وبذلك نُعرّف loss function كما يلي:

نحسب متوسّط الخسارة، حيث m هو حجم مجموعة التدريب.
تصنيف الصور
LeNet, التعرّف على الأرقام
LeNet معمارية طوّرها Yann Lecun وتهدف إلى الكشف عن الرقم الموجود في الإدخال.
بمعطى صور gray-scale لأرقام hand-written من 0 إلى 9، تتنبّأ الشبكة العصبية الالتفافية بالرقم الموجود في الصورة.
تُسمّى مجموعة التدريب MNIST، وهي dataset تحتوي على أكثر من 70 ألف صورة بأبعاد 28x28x1 بكسل. تمتلك الشبكة العصبية المعمارية التالية وتضمّ أكثر من 60 ألف بارامتر:
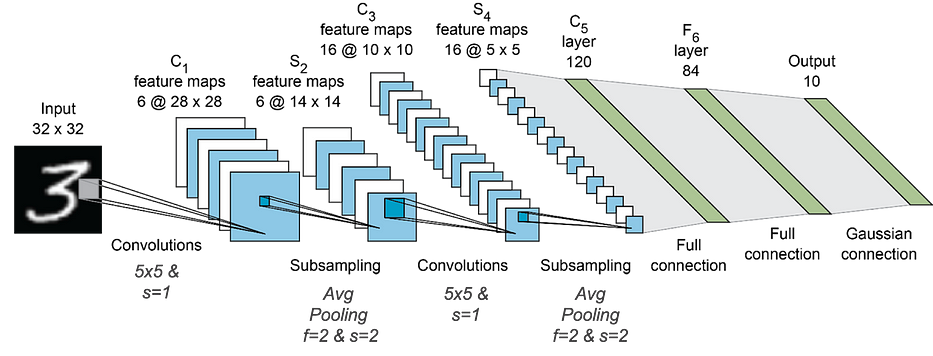
لمزيد من التفاصيل، أنصحك بقراءة الورقة الرسمية.
AlexNet
AlexNet معمارية شهيرة فازت بمسابقة ImageNet في 2012. وهي مشابهة لـ LeNet لكنها تحوي مزيدًا من الطبقات وdropouts ودالة تنشيط ReLU في معظم الأحيان.
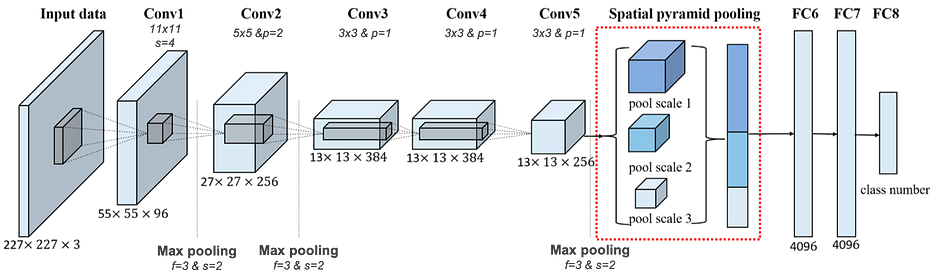
مجموعة التدريب هي مجموعة فرعية من ImageNet database، وهي 15 مليون صورة موسومة ذات دقّة عالية وتمثّل أكثر من 22 ألف فئة.
استخدمت AlexNet أكثر من 1.2 مليون صورة في مجموعة التدريب، و50 ألفًا في مجموعة التحقّق، و150 ألفًا في مجموعة الاختبار، وأُعيد تحجيمها جميعًا إلى 227x227x3. تمتلك المعمارية أكثر من 60 million parameters ولذلك جرى تدريبها على 2 GPUs، وتُخرج softmax vector بحجم (1000,1).
لمزيد من المعلومات، أنصحك بقراءة الورقة الرسمية.
VGG-16
VGG-16 شبكة عصبية التفافية لتصنيف الصور، دُرّبت على نفس الـ dataset ImageNet ولديها أكثر من 138 million parameters دُرّبت على GPUs.
المعمارية هي التالية:
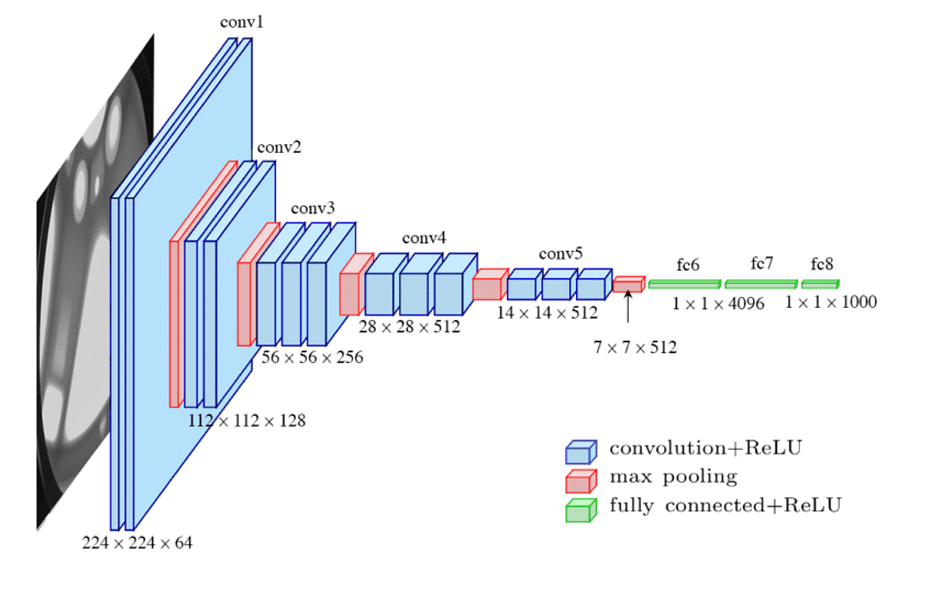
إنها أكثر دقّة وأعمق من AlexNet لأنها استبدلت النوى الكبيرة 11x11x5 و5x5 بنوى متتالية 3x3.
لمزيد من التفاصيل، تحقّق من الورقة الرسمية لمشروع VGG.
الكشف عن الأشياء - YOLOv3
الكشف عن الأشياء هو مهمّة الكشف عن عدّة كائنات في صورة، وتشمل كلًّا من توطين الكائن وتصنيفه. مقاربة أوّلية بسيطة تتمثّل في تمرير نافذة بأبعاد قابلة للتخصيص والتنبّؤ في كلّ مرّة بفئة المحتوى باستخدام شبكة مدرّبة على صور مقصوصة. هذه العملية ذات تكلفة حسابية عالية ويمكن لحسن الحظ أتمتتها باستخدام الالتفافات.
تشير YOLO إلى You Only Look Once، والفكرة الأساسية تتمثّل في وضع شبكة (grid) على الصورة (عادةً 19x19) حيث:
خليّة واحدة فقط، وهي الخلية التي تحتوي على مركز/منتصف الكائن مسؤولة عن الكشف عن هذا الكائن
تُوسَم كل خلية من الشبكة (i,j) على النحو التالي:

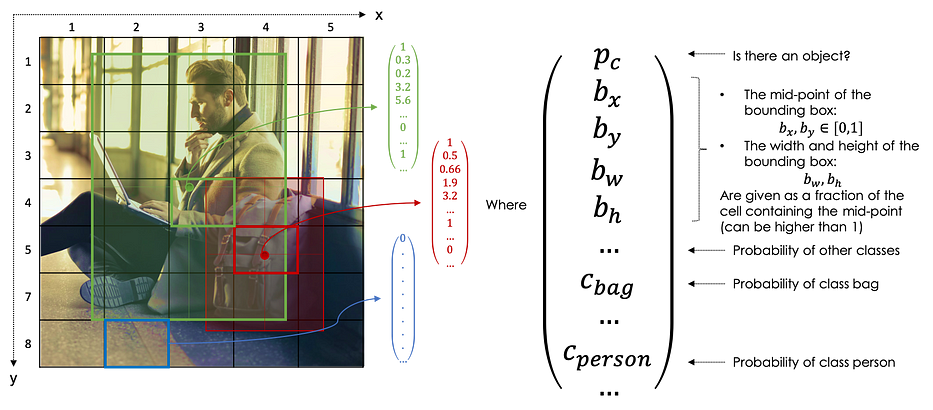
وبالتالي، لكل صورة يكون الإخراج المستهدف بحجم:
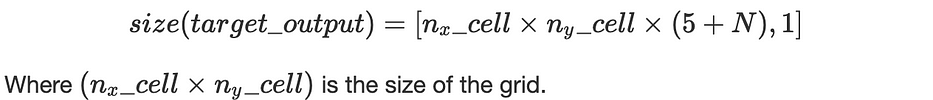
IOU & NMS
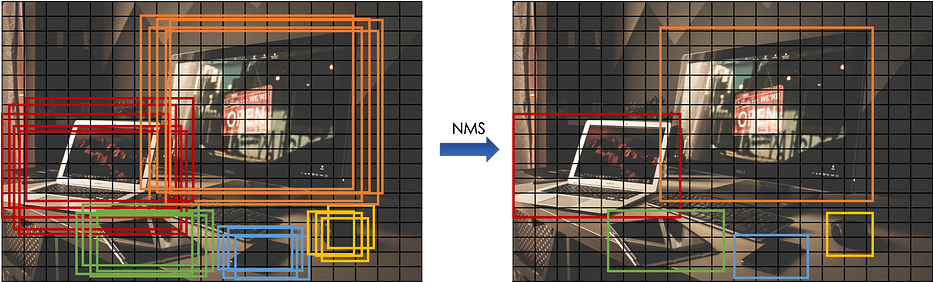
من أجل تقييم توطين الكائن، نستخدم Intersection Over Union التي تقيس overlap بين صندوقَي إحاطة:

عند التنبّؤ بصندوق الإحاطة لكائن معيّن في خلية معيّنة من الشبكة، قد تُعطى مخرجات عديدة، وتساعد Non-Max Suppression في الكشف عن الكائن only once. فهي تأخذ أعلى احتمالية وتُلغي الصناديق الأخرى التي تتشارك في تداخل عالٍ (IOU).
لكلّ خلية من الشبكة، تكون الخوارزمية كالتالي:

Anchor Boxes
في معظم الحالات، قد تحتوي خلية الشبكة على multiple objects، وتسمح صناديق الإرساء (anchor boxes) بالكشف عنها جميعًا. في حالة 2 anchor boxes، تُوسَم كلّ خلية من الشبكة على النحو التالي:
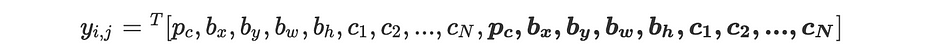

وبشكل أعمّ، يكون حجم الإخراج المستهدف:
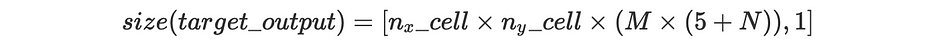
حيث N هو عدد الفئات وM عدد anchor boxes.
خوارزمية YOLOv3
دُرّبت YOLO على coco dataset، وهي قاعدة بيانات واسعة النطاق للكشف عن الأشياء وتجزئتها ووصفها مع 80 فئة من الكائنات. تمتلك YOLOv3 معمارية Darknet-53 كمستخرج للسمات ويُعرف أيضًا بـ backbone.
يجري التدريب عبر تصغير loss function باستخدام طرق التدرّج كذلك.
وهي combined من:
- خسارة logistic regression على p_c
- خسارة Squared error بالنسبة إلى b_i
- خسارة Softmax(cross-entropy) للاحتمالات c_i
في كلّ epoch، وفي كلّ خلية، نولّد الإخراج y_(i,j) ونُجري evaluate لدالّة الخسارة.
عند إجراء التنبّؤات، نتحقّق من أنّ p_c مرتفع بما يكفي، ولكلّ خلية من الشبكة، نتخلّص من التنبّؤات ذات الاحتمالية المنخفضة ونستخدم non-max suppression لكلّ فئة لتوليد الإخراج النهائي.
لمزيد من المعلومات، أنصحك بقراءة الورقة الرسمية.
التعرّف على الوجوه - Siamese Networks
الشبكات السيامية هي شبكات عصبية، التفافية في الغالب، تسمح بحساب درجة التشابه بين إدخالَين، صورتَين في حالتنا، على النحو التالي:
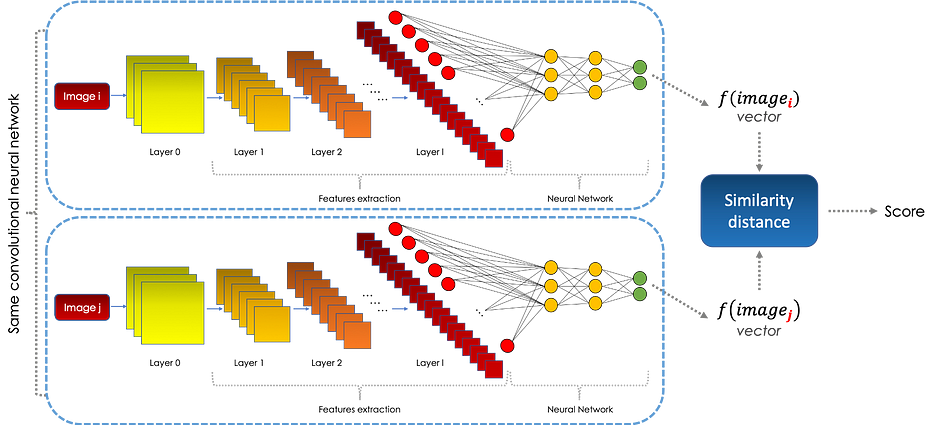
الغرض من وحدة CNN هو تمثيل المعلومات في الصورة في فضاء آخر، يُسمّى embedding space بفضل دالّة. ثمّ نقارن الـ embeddings باستخدام مسافة معيّنة. يتمّ التعلّم في الشبكات السيامية عن طريق تصغير دالّة هدف مكوّنة من loss function تُسمّى triplet.
تأخذ دالّة triplet 3 متغيّرات متجهية كإدخال: مرساة A، وإيجابي P (مشابه لـ A)، وسلبي أخير N (يختلف عن A). وبالتالي، نسعى إلى الحصول على:
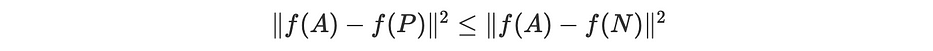
حيث ∥x∥²=<x,x> بحاصل ضرب سُلَّمي معيّن.
لمنع الدالّة المُتعلَّمة f من أن تكون منعدمة، نُعرّف الهامش 0<α≤1 بحيث:
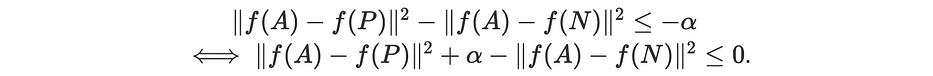
وبذلك، نُعرّف دالّة loss كما يلي:
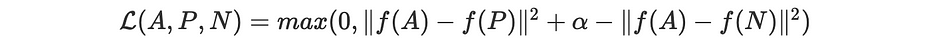
انطلاقًا من قاعدة بيانات تعلّم بحجم n، تكون دالّة الهدف المراد تصغيرها هي:
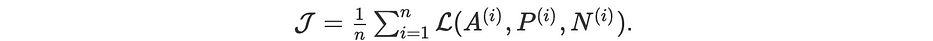
عند تدريب المعمارية ولكلّ epoch، نُثبّت عدد triplets ولكلّ واحد:
- نختار عشوائيًا صورتَين من الفئة نفسها (Anchor وPositive)
- نختار عشوائيًا صورة من فئة أخرى (Negative)
يمكن أن تكون triplet (A, N, P):
- Easy negative، عندما ∥f(A)−f(P)∥²+α−∥f(A)−f(N)∥²≤0
- Semi-hard negative، عندما ∥f(A)−f(P)∥²+α>∥f(A)−f(N)∥²>∥f(A)−f(P)∥²
- Hard negative، عندما ∥f(A)−f(N)∥²<∥f(A)−f(P)∥²
نختار عادةً التركيز على semi-hard negatives لتدريب الشبكة العصبية.
تطبيق: التعرّف على الوجوه
يمكن استخدام الشبكات السيامية لتطوير نظام قادر على التعرّف على الوجوه. بمعطى صورة ملتقطة بكاميرا، تُقارنها المعمارية بكلّ الصور في قاعدة البيانات.
وبما أنّه لا يمكن أن تكون لدينا صور متعدّدة للشخص نفسه في قاعدة بياناتنا، فإننا نُدرّب عادةً الشبكة السيامية على imageset مفتوح المصدر غني بما يكفي لإنشاء triplets.
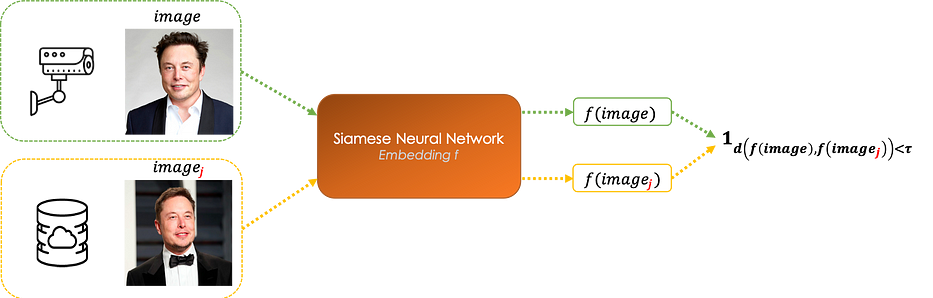
تتعلّم الشبكة العصبية الالتفافية دالّة تشابه f وهي embedding للصورة.
بمعطى صورة الكاميرا، نُقارنها بكلّ image_j من قاعدة البيانات بحيث:
- إذا كان d(f(image, image_j))≤τ، تمثّل الصورتان الشخص نفسه
- إذا كان d(f(image, image_j))>τ، تكون الصورتان لشخصَين مختلفَين
نختار الوجه image_j الأقرب إلى image من حيث المسافة d. ويُختار العتبة τ بحيث يكون F1-score هو الأعلى مثلًا.
الخاتمة
تُعدّ CNNs معماريات مستخدمة على نطاق واسع في معالجة الصور، فهي تُتيح نتائج أفضل وأسرع. وقد استُخدمت مؤخّرًا أيضًا في معالجة النصوص حيث يكون إدخال الشبكة هو embedding للـ tokens بدلًا من البكسلات في الصور.
لا تتردّد في الاطلاع على مقالاتي السابقة التي تناقش:
- Deep Learning’s mathematics
- Convolutional Neural Networks’ mathematics
- Recurrent Neural Networks
المراجع
- Deep Learning Specialization, Coursera, Andrew Ng
- Machine Learning, Loria, Christophe Cerisara