
Deep learning مجال فرعي من Machine Learning Science يستند إلى الشبكات العصبية الاصطناعية. لها عدّة مشتقّات مثل Multi-Layer Perceptron -MLP-، Convolutional Neural Networks -CNN- وRecurrent Neural Networks -RNN- التي يمكن تطبيقها على مجالات كثيرة بما في ذلك Computer Vision، Natural Language Processing، Machine Translation…
ينطلق deep learning لثلاثة أسباب رئيسية:
- هندسة سمات بديهية: بينما تتطلّب معظم خوارزميات machine learning خبرة بشرية لهندسة واستخراج السمات، يُعالج deep learning تلقائيًا اختيار المتغيّرات وأوزانها
- قواعد بيانات ضخمة: أدّى الجمع المستمرّ للبيانات إلى قواعد بيانات كبيرة تسمح بشبكات عصبية أعمق
- تطوّر الأجهزة: GPUs الجديدة، اختصارًا لـ Graphical Process Units، تسمح بحساب جبري أسرع وهو القاعدة الأساسية لـ DL
في هذه المدوّنة، سنُركّز بشكل رئيسي على Multi-Layer Perceptron -MLP- حيث سنُفصّل الخلفية الرياضية وراء نجاح deep learning ونستكشف خوارزميات التحسين المستخدمة لتحسين أدائه.
الملخّص كالتالي:
- التعريف
- خوارزمية التعلّم
- تهيئة البارامترات
- Forward, Backpropagation
- دوال التنشيط
- خوارزمية التحسين
ملاحظة: بما أنّ Medium لا يدعم LaTeX، تمّ إدراج التعبيرات الرياضية كصور. لذا أنصحك بإيقاف الوضع الداكن للحصول على تجربة قراءة أفضل.
التعريف
الخليّة العصبية
إنها كتلة من العمليات الرياضية تربط كيانات
لننظر في المشكلة التي نُقدّر فيها سعر منزل بناءً على حجمه، يمكن تخطيطها على النحو التالي:
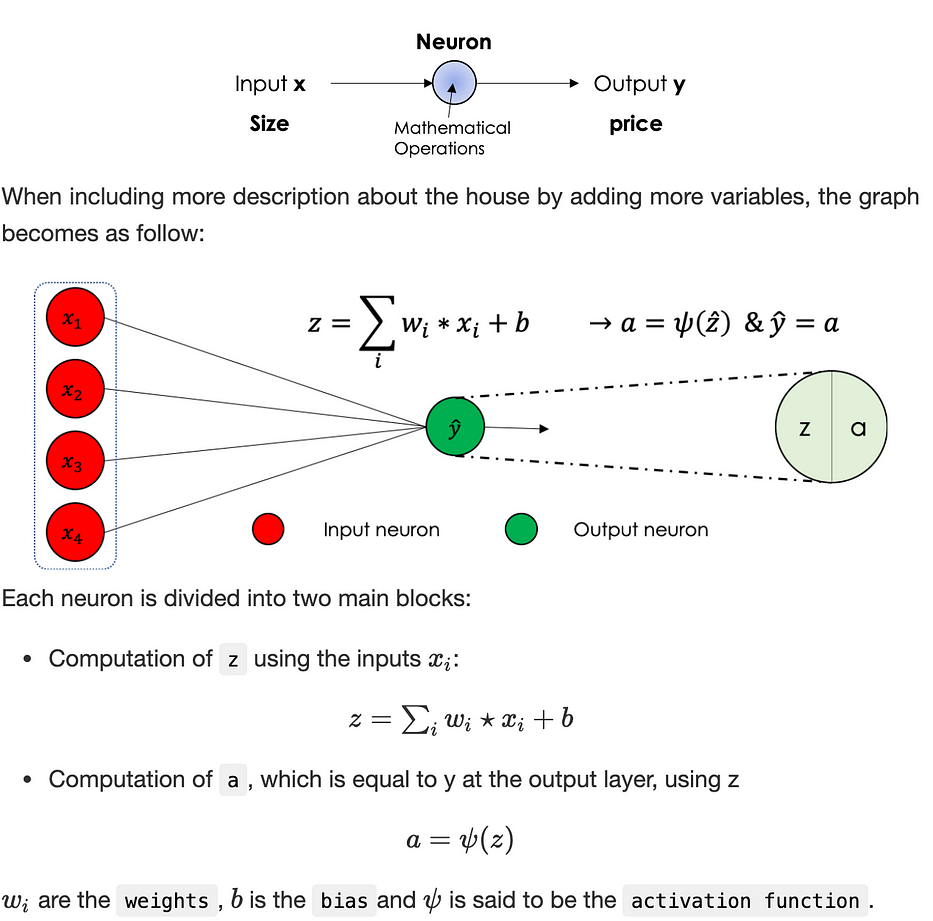
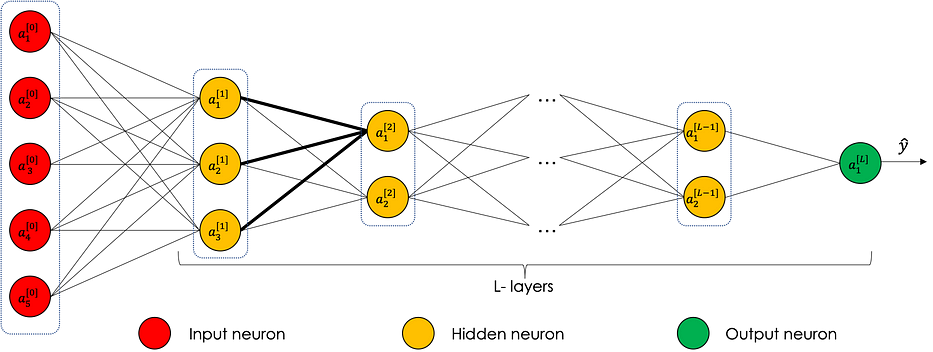
بشكل عامّ، الشبكات العصبية المعروفة بـ MLP، اختصارًا لـ ‘Multi Layers Perceptron’، نوع من الشبكات العصبية الرسمية المباشرة المنظّمة في عدّة طبقات تتدفّق فيها المعلومات من طبقة الإدخال إلى طبقة الإخراج فقط.
تتكوّن كلّ طبقة من عدد محدّد من الخلايا العصبية، نُميّز:
- طبقة الإدخال
- الطبقات المخفيّة
- طبقة الإخراج
الرسم البياني التالي يمثّل شبكة عصبية بـ 5 خلايا عصبية في الإدخال، 3 في الطبقة المخفيّة الأولى، 3 في الطبقة المخفيّة الثانية و2 في الإخراج.
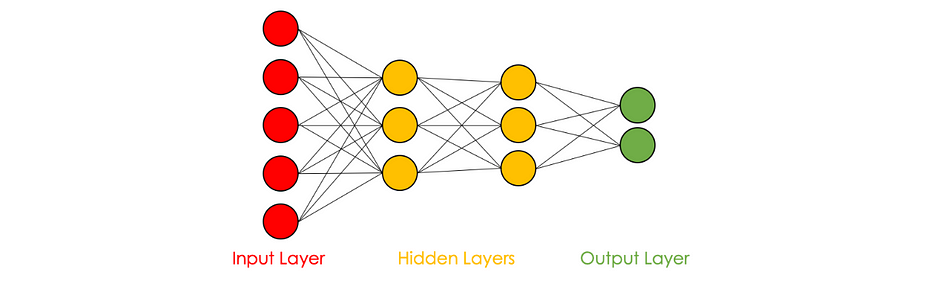
يمكن تفسير بعض المتغيّرات في الطبقات المخفيّة بناءً على سمات الإدخال: في حالة تسعير المنازل وتحت افتراض أنّ الخليّة العصبية الأولى من الطبقة المخفيّة الأولى تُولي اهتمامًا أكبر للمتغيّرات x_1 وx_2، يمكن تفسيرها على أنها تكميم لحجم العائلة للمنزل مثلًا.
DL كمهمّة supervised
في معظم مشاكل DL، نميل إلى التنبّؤ بإخراج y باستخدام مجموعة من المتغيّرات X، في هذه الحالة، نفترض أنّه لكلّ صف من قاعدة البيانات X_i لدينا التنبّؤ المقابل y_i، وبالتالي البيانات الموسومة.
التطبيقات: العقارات، التعرّف على الكلام، تصنيف الصور…
يمكن أن تكون البيانات المستخدمة:
- Structured: قواعد بيانات صريحة بسمات محدّدة جيّدًا
- Unstructured: صوت، صورة، نصّ،…
نظرية التقريب الكلّي
Deep learning في الحياة الواقعية هو تقريب لدالّة f مُعطاة. هذا التقريب ممكن ودقيق بفضل النظرية التالية:

(*) في البعد المنتهي، يُقال إنّ مجموعة متراصّة إذا كانت مغلقة ومحدودة. زر هذا الرابط لمزيد من التفاصيل.
الخلاصة الرئيسية لهذه الخوارزمية هي أنّ deep learning يسمح بحلّ أيّ مشكلة يمكن التعبير عنها رياضيًا
المعالجة المسبقة للبيانات
في أيّ مشروع machine learning بشكل عامّ، نُقسّم بياناتنا إلى 3 مجموعات:
- Train set: تُستخدم لتدريب الخوارزمية وبناء batches
- Dev set: تُستخدم لضبط الخوارزمية وتقييم الانحياز والتباين
- Test set: تُستخدم لتعميم الخطأ/الدقّة للخوارزمية النهائية
الجدول التالي يُلخّص توزيع المجموعات الثلاث بحسب حجم dataset m:
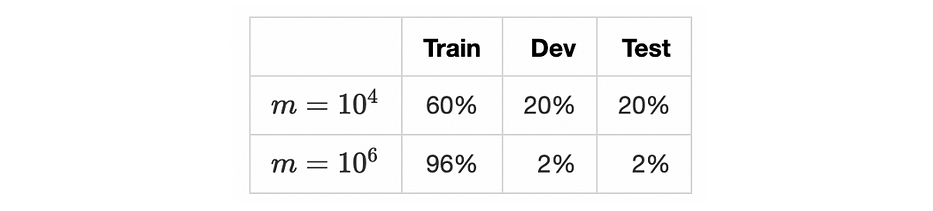
تتطلّب خوارزميات deep learning القياسية dataset كبيرة حيث يكون عدد العيّنات حول الأسطر. الآن وبعد أن أصبحت البيانات جاهزة سنرى في القسم التالي خوارزمية التدريب.
عادةً، قبل تقسيم البيانات، نُطبّع المدخلات أيضًا، وهي خطوة مفصّلة لاحقًا في هذا المقال.
خوارزمية التعلّم
التعلّم في الشبكات العصبية هو خطوة حساب أوزان البارامترات المرتبطة بالانحدارات المختلفة في جميع أنحاء الشبكة. وبعبارة أخرى، نهدف إلى إيجاد أفضل البارامترات التي تُعطي أفضل تنبّؤ/تقريب، انطلاقًا من الإدخال، للقيمة الحقيقية.
لذلك، نُعرّف دالّة هدف تُسمّى loss function ويُرمز إليها بـ J تُكمّم المسافة بين القيم الحقيقية والمتنبّأ بها على مجموعة التدريب الكاملة.
نُصغّر J باتّباع خطوتَين رئيسيتَين:
- Forward Propagation: نُمرّر البيانات عبر الشبكة إمّا كاملةً أو على دفعات، ونحسب loss function على هذه الدفعة وهي ليست إلّا مجموع الأخطاء المرتكبة عند الإخراج المتنبّأ به للصفوف المختلفة.
- Backpropagation: تتمثّل في حساب gradients لدالّة التكلفة بالنسبة للبارامترات المختلفة، ثمّ تطبيق خوارزمية انحدار لتحديثها.
نُكرّر العملية نفسها عددًا من المرّات يُسمّى epoch number. بعد تعريف المعمارية، تُكتب خوارزمية التعلّم على النحو التالي:

(∗) تُقيّم دالّة التكلفة L المسافات بين القيمة الحقيقية والمتنبّأ بها عند نقطة واحدة.
تهيئة البارامترات
الخطوة الأولى بعد تعريف معمارية الشبكة العصبية هي تهيئة البارامترات. وهي تعادل حقن ضوضاء أوّلية في أوزان النموذج.
- تهيئة بصفر: يمكن للمرء أن يفكّر في تهيئة البارامترات بأصفار في كلّ مكان، أي: W=0 وb=0
باستخدام معادلات forward propagation، نُلاحظ أنّ جميع الوحدات المخفيّة ستكون متماثلة ممّا يُعاقب مرحلة التعلّم.
- تهيئة عشوائية: إنّه بديل يُستخدم عادةً ويتمثّل في حقن ضوضاء عشوائية في البارامترات. إذا كانت الضوضاء كبيرة جدًّا، قد تُشبَع بعض دوال التنشيط ممّا قد يؤثّر لاحقًا على حساب gradient.
اثنتان من أشهر طرق التهيئة هما:
Xavier: تتمثّل في ملء البارامترات بقيم مُختارة عشوائيًا من متغيّر مركزي يتبع التوزيع الطبيعي:
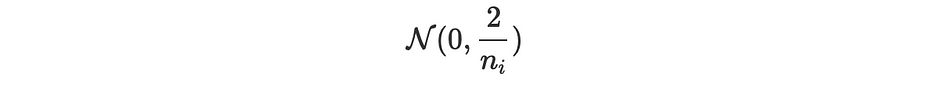
Glorot: المقاربة نفسها مع تباين مختلف:
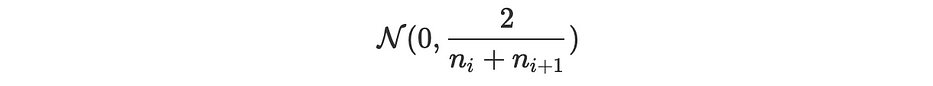
Forward وBackpropagation
قبل التعمّق في الجبر وراء deep learning، سنُحدّد أوّلًا الترميز الذي سيُستخدم في توضيح معادلات كلّ من forward وbackpropagation.
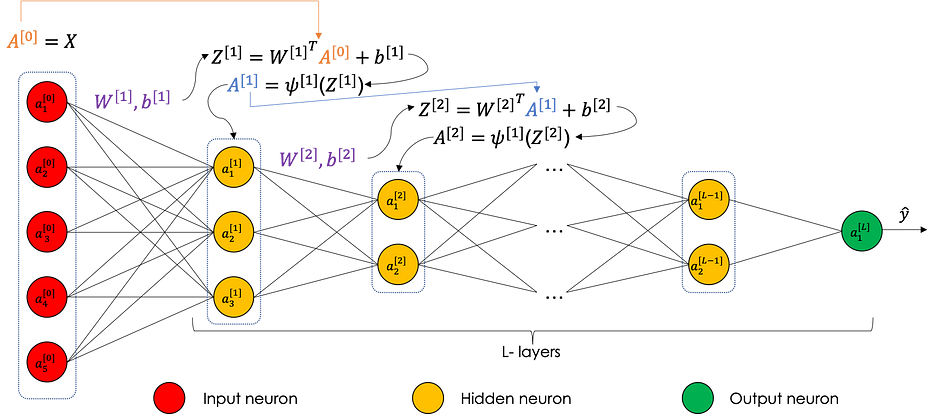
تمثيل الشبكة العصبية
الشبكة العصبية هي تسلسل من regressions متبوع بـ activation function. كلاهما يُعرّف ما نُسمّيه forward propagation. وهما البارامترات المُتعلَّمة في كلّ طبقة. backpropagation هي أيضًا تسلسل من العمليات الجبرية تُجرى من الإخراج باتّجاه الإدخال.
Forward propagation
- الجبر عبر الشبكة
لننظر في شبكة عصبية بـ L layers على النحو التالي:

الجبر عبر مجموعة التدريب
لننظر في التنبّؤ بإخراج إطار بيانات بصف واحد، عبر الشبكة العصبية.

عند التعامل مع dataset مكوّن من m صف، يكون تكرار هذه العمليات بشكل منفصل لكلّ سطر مكلفًا جدًّا.
لدينا، في كلّ طبقة [i]:

البارامتر b_i يستخدم broadcasting لتكرار نفسه عبر الأعمدة. يمكن تلخيص ذلك في الرسم البياني التالي:
Backpropagation
backpropagation هي الخطوة الثانية من التعلّم، التي تتمثّل في حقن الخطأ المُرتكب في مرحلة التنبّؤ (forward) داخل الشبكة وتحديث بارامتراتها لأداء أفضل في التكرار التالي.
ومن ثَمَّ، تحسين الدالّة J، عادةً عبر طريقة الانحدار.
الرسم البياني الحسابي
تتطلّب معظم طرق الانحدار حساب gradient لدالّة الخسارة المُرمز إليها بـ ∇J(θ).
في شبكة عصبية، تُجرى العملية باستخدام رسم بياني حسابي يُحلّل الدالّة J إلى عدّة متغيّرات وسيطة.
لننظر في الدالّة التالية: f(x,y,z)=(x+y).z
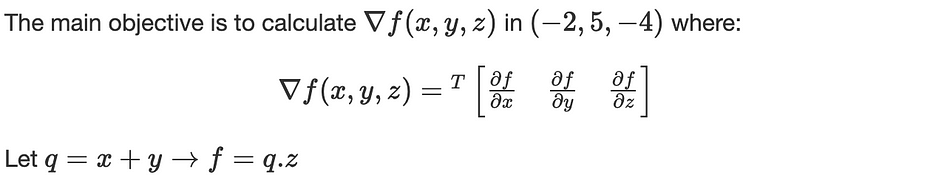
نُجري الحساب باستخدام تمريرتَين:
- Forward propagation: يحسب قيمة f من المدخلات إلى الإخراج: f(−2,5,−4)=−12
- Backpropagation: يُطبّق بشكل تكراري قاعدة السلسلة لحساب gradients من الإخراج إلى المدخلات:
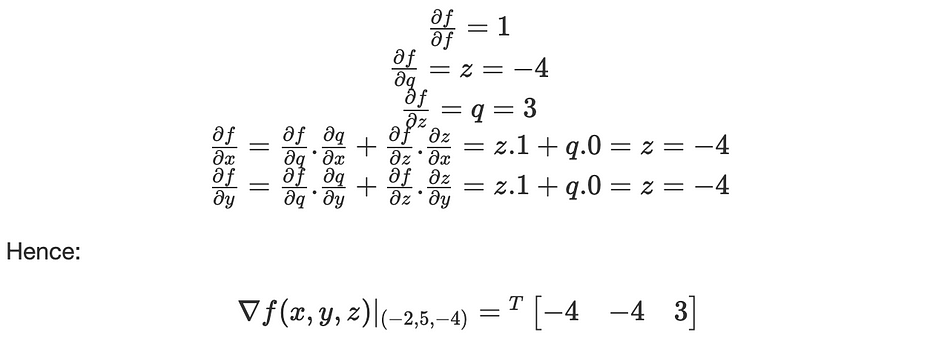
يمكن تلخيص المشتقّات في computational graph التالي:
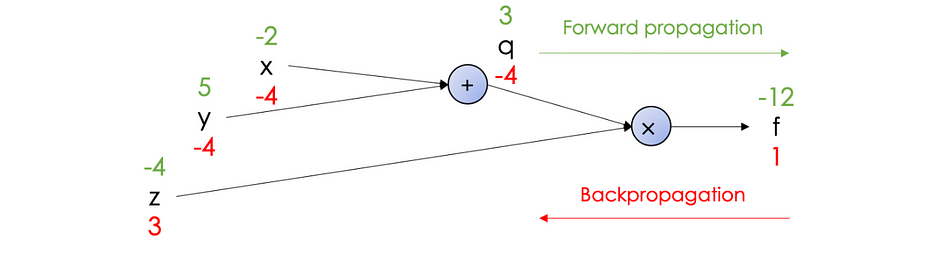
المعادلات
رياضيًا، نحسب gradients لدالّة التكلفة J، بالنسبة لبارامترات المعمارية W وb.
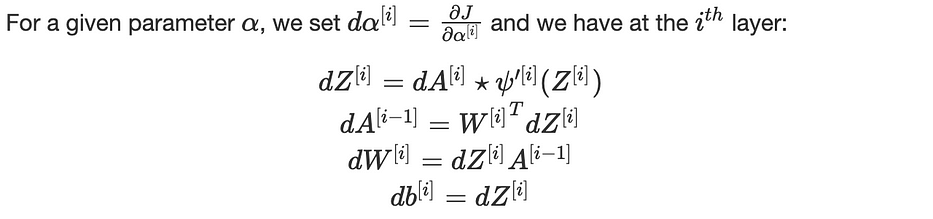
حيث (⋆) هي الضرب عنصرًا بعنصر.
نُطبّق هذه المعادلات بشكل تكراري لـ i=L, L−1,…,1
Gradient Checking
عند إجراء backpropagation، تُضاف عملية فحص إضافية للتأكّد من أنّ الحسابات الجبرية صحيحة.
الخوارزمية:

يجب أن تكون قريبة من قيمة ϵ، يُشتبه بوجود خطأ عندما تكون قيمة الكمّية أعلى بـ ألف مرّة من ϵ.
يمكننا تلخيص Forward وBackward propagation في الكتلة التالية:
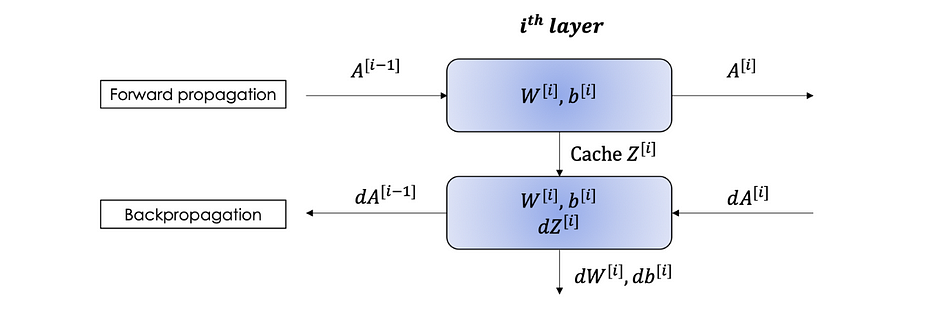
البارامترات مقابل Hyperparameters
-Parameters، المُرمز إليها بـ θ، هي العناصر التي نتعلّمها عبر التكرارات والتي نُطبّق عليها backpropagation ونُحدّث: W وb.
-Hyperparameters هي جميع المتغيّرات الأخرى التي نُعرّفها في خوارزميتنا والتي يمكن ضبطها لتحسين الشبكة العصبية:
- Learning rate α
- عدد التكرارات
- اختيار دوال التنشيط
- عدد الطبقات L
- عدد الوحدات في كلّ طبقة
دوال التنشيط
دوال التنشيط هي نوع من دوال النقل التي تختار البيانات المُمرَّرة في الشبكة العصبية. التفسير الكامن هو السماح لخليّة عصبية في الشبكة بنشر بيانات التعلّم (إذا كانت في مرحلة التعلّم) فقط إذا كانت متحمّسة بما يكفي.
إليك قائمة بأكثر الدوال شيوعًا:
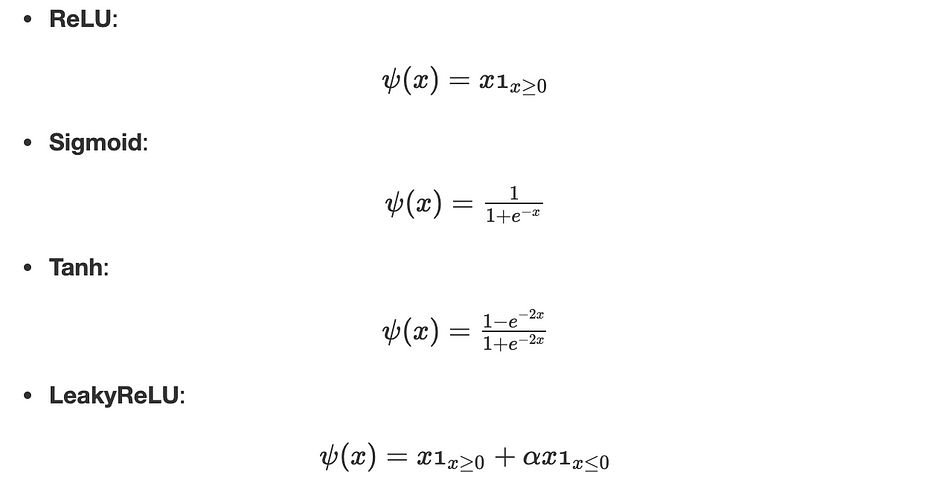
ملاحظة: إذا كانت جميع دوال التنشيط خطّية، فإنّ الشبكة العصبية تكافئ تمامًا انحدارًا خطيًّا بسيطًا
خوارزمية التحسين
المخاطرة
لننظر في شبكة عصبية مُرمز إليها بـ f. الهدف الحقيقي للتحسين يُعرَّف بأنه الخسارة المتوقّعة على جميع المُجمَلات:
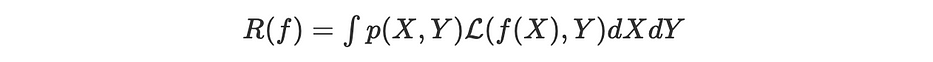
حيث X عنصر من فضاء مستمرّ من المُلاحظات التي تُقابلها مستهدفة Y وp(X,Y) هي الاحتمالية الهامشية لمُلاحظة الزوج (X,Y).
المخاطرة التجريبية
بما أنّه لا يمكننا الحصول على جميع المُجمَلات وبالتالي نتجاهل التوزيع، نُقيّد تقدير المخاطرة على dataset معيّن مُمثِّل بشكل جيّد للمُجمَلات الكلّية ونعتبر جميع الحالات متساوية الاحتمالية.
في هذه الحالة: نضع m حجم المُجمل المُمثِّل، نحصل على: ∫=∑ وp(X,Y)=1/m. ومن ثَمَّ، نُحسّن بشكل تكراري دالّة الخسارة المُعرّفة على النحو التالي:
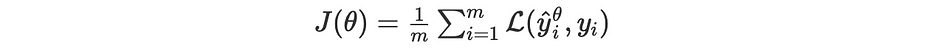
بالإضافة إلى أنّه يمكننا التأكيد بأنّ:
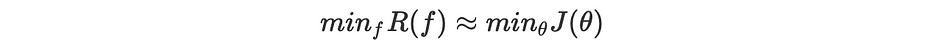
توجد العديد من التقنيات والخوارزميات، المعتمدة بشكل رئيسي على gradient descent، التي تُجري التحسين. في الأقسام أدناه، سنتطرّق إلى أشهرها. من المهمّ ملاحظة أنّ هذه الخوارزميات قد تعلق في minima محلّية ولا شيء يضمن الوصول إلى الكلّية.
تطبيع المدخلات
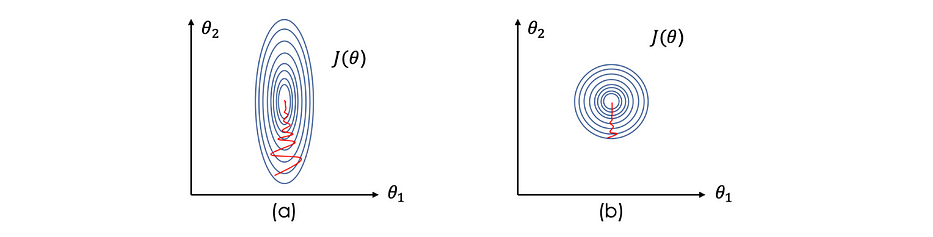
قبل تحسين دالّة الخسارة، نحتاج إلى تطبيع المدخلات لتسريع التعلّم. في هذه الحالة، تصبح J(θ) أكثر إحكامًا وتناسقًا ممّا يساعد gradient descent على إيجاد الحدّ الأدنى بشكل أسرع وبالتالي في تكرارات أقلّ.
Standard data هي المقاربة الشائعة الاستخدام التي تتمثّل في طرح متوسّط المتغيّرات والقسمة على انحرافها المعياري. باعتبار ذلك، الصورة التالية توضّح تأثير تطبيع الإدخال على خطوط الكنتور -standard data على اليمين-:
لتكن X متغيّرًا في قاعدة بياناتنا، نضع:
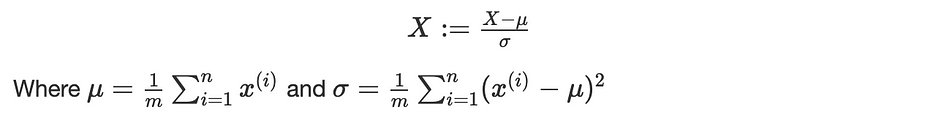
Gradient descent
بشكل عامّ، نميل إلى بناء دالّة J convex وdifferentiable حيث يكون أيّ minimum محلّي هو كلّي. رياضيًا، إيجاد الحدّ الأدنى الكلّي لدالّة محدّبة يُكافئ حلّ المعادلة ∇J(θ)=0، نُرمز إلى حلّها بـ θ⋆.
معظم الخوارزميات المستخدمة من النوع:

Mini-batch gradient descent
تتمثّل هذه التقنية في تقسيم مجموعة التدريب إلى batches:

اختيار حجم mini-batch:
- عدد صغير من الصفوف ∼2000 سطر
- الحجم النموذجي: قوّة لـ 2 وهو جيّد للذاكرة
- يجب أن يتناسب Mini-batch مع ذاكرة CPU/GPU
ملاحظة: في حالة وجود سطر بيانات واحد فقط في batch، تُسمّى الخوارزمية stochastic gradient descent
Gradient descent مع momentum
تنويع لـ gradient descent يتضمّن مفهوم momentum، الخوارزمية كالتالي:
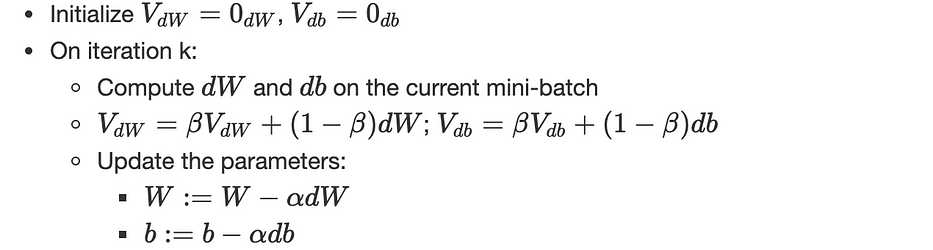
(α,β) هي hyperparameters.
بما أنّ dθ يُحسب على mini-batch، فإنّ gradient الناتج ∇J صاخب جدًّا، هذه المتوسّطات الموزّنة أسّيًا التي يضمّنها momentum تُعطي تقديرًا أفضل للمشتقّات.
RMSprop
Root Mean Square prop مشابه جدًّا لـ gradient descent مع momentum، الفرق الوحيد هو أنه يتضمّن momentum من الدرجة الثانية بدلًا من الأولى، بالإضافة إلى تغيير طفيف على تحديث البارامترات:
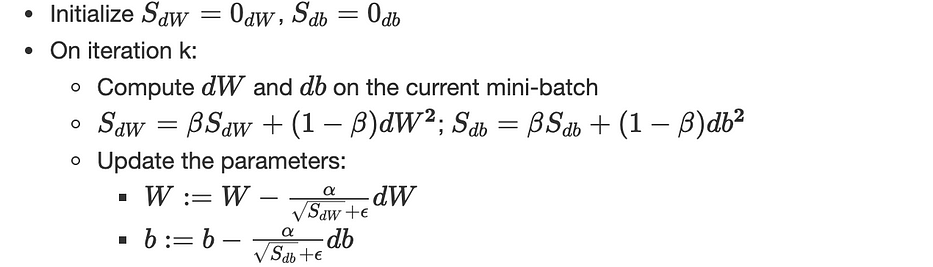
(α,β) هي hyperparameters وϵ تضمن الاستقرار العددي (≈10−8)
Adam
Adam هي خوارزمية تحسين معدّل تعلّم متكيّفة مصمّمة خصّيصًا لتدريب الشبكات العصبية العميقة. يمكن النظر إلى Adam على أنها مزيج من RMSprop وgradient descent مع momentum.
تستخدم gradients مربّعة لتعيين معدّل التعلّم بمقياس مثل RMSprop وتستفيد من momentum باستخدام المتوسّط المتحرّك لـ gradient بدلًا من gradient نفسه كما ينحدر gradient مع momentum.
الفكرة الرئيسية هي تجنّب التذبذبات أثناء التحسين بتسريع الانحدار في الاتجاه الصحيح.
خوارزمية Adam optimizer هي التالية:

تخفيف معدّل التعلّم
الهدف الرئيسي من تخفيف معدّل التعلّم هو تقليل معدّل التعلّم ببطء بمرور الوقت/التكرارات. يجد هذا تبريره في حقيقة أنّنا نستطيع اتّخاذ خطوات كبيرة في بداية التعلّم لكن عند الاقتراب من الحدّ الأدنى الكلّي، نُبطئ وبالتالي نُقلّل من معدّل التعلّم.
توجد العديد من قوانين تخفيف معدّل التعلّم، إليك بعضًا من أكثرها شيوعًا:

Regularization
التباين/الانحياز
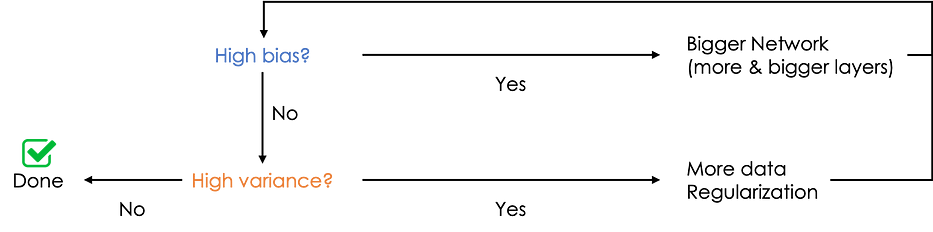
عند تدريب شبكة عصبية، قد تُعاني من:
- High bias: أو underfitting، حيث تفشل الشبكة في إيجاد المسار في البيانات، في هذه الحالة، J_train عالٍ جدًّا وكذلك J_dev. رياضيًا، عند إجراء cross-validation؛ يكون متوسّط J على جميع الـ folds المُعتبَرة عاليًا.
- High variance أو overfitting، يتناسب النموذج تمامًا مع بيانات التدريب لكنه يفشل في التعميم على البيانات غير المرئية، في هذه الحالة، J_train منخفض جدًّا وJ_dev عالٍ نسبيًا. رياضيًا، عند إجراء cross-validation؛ يكون تباين J على جميع الـ folds المُعتبَرة عاليًا.
لننظر في لعبة لوحة الرماية، حيث ضرب الهدف الأحمر هو السيناريو الأفضل. وجود low bias (السطر الأوّل) يعني أنّنا في المتوسّط قريبون من الهدف. في حالة low variance، تتركّز الضربات جميعها حول الهدف (تباين توزيع الضربات منخفض). عندما يكون التباين عاليًا، تحت افتراض low bias، تنتشر الضربات لكن لا تزال حول الدائرة الحمراء.
والعكس بالعكس، يمكننا تعريف high bias مع low/high variance.
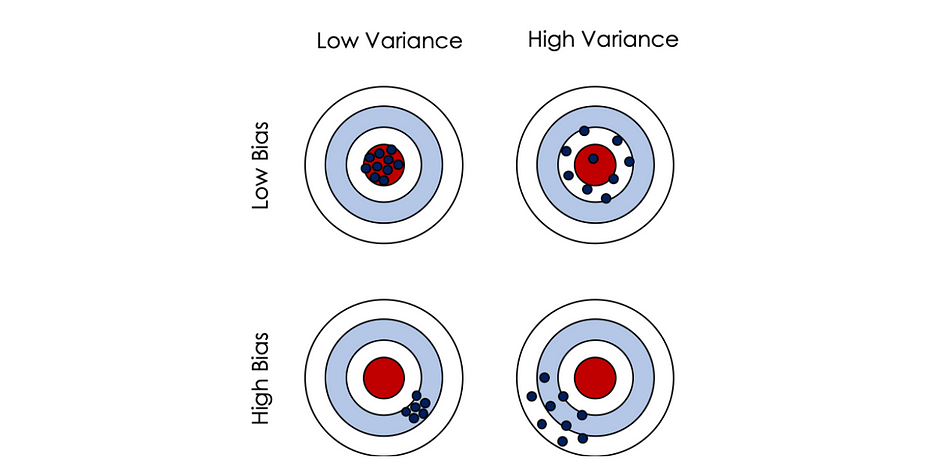
رياضيًا، لتكن f دالّة انحدار حقيقية: y=f(x)+ϵ حيث: ϵ~N(0,σ²)
نُلائم فرضية h(x)=Wx+b بـ MSE ونعتبر x_0 نقطة بيانات جديدة، y_0=f(x_0)+ϵ: يمكن تعريف الخطأ المتوقَّع بـ:
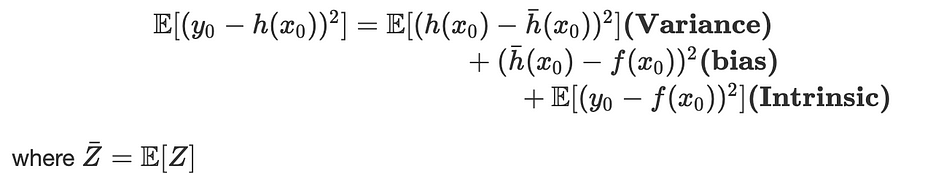
يجب إيجاد توازن بين التباين والانحياز للعثور على التعقيد الأمثل للنموذج إمّا باستخدام معيار AIC أو باستخدام cross-validation.
إليك مخطّط بسيط لاتّباعه لحلّ مشاكل bias/variance:
L1, L2 regularization
Regularization تقنية تحسين تمنع overfitting.
تتمثّل في إضافة مصطلح في دالّة الهدف لتصغيره على النحو التالي:
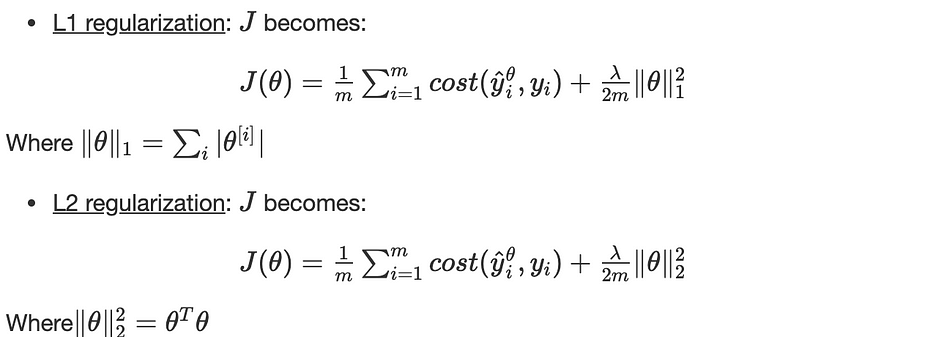
λ هو hyperparameter الخاصّ بـ regularization.
Backpropagation وregularization
يعتمد تحديث البارامترات أثناء backpropagation على gradient ∇J، الذي يُضاف إليه مصطلح regularization جديد. في L2 regularization، يصبح على النحو التالي:
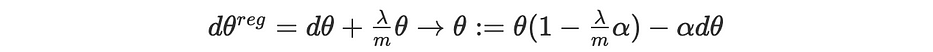
باعتبار λ>>1، يؤدّي تصغير دالّة التكلفة إلى قيم ضعيفة للبارامترات بسبب مصطلح (λ/2m)∥θ∥ الذي يُبسّط الشبكة ويجعلها أكثر اتّساقًا، وبالتالي أقلّ تعرّضًا لـ overfitting.
Dropout regularization
بشكل عامّ، الفكرة الرئيسية هي أخذ عيّنة متغيّر عشوائي منتظم، for each layer for each node، ولديه احتمالية p للاحتفاظ بالعقدة و1−p لإزالتها ممّا يُقلّل من الشبكة.
الحدس الرئيسي لـ dropout يستند إلى فكرة أنّ الشبكة لا يجب أن تعتمد على سمة معيّنة بل يجب أن تنشر الأوزان!
رياضيًا، عندما يكون dropout مُعطّلًا وباعتبار العقدة j من الطبقة i، لدينا المعادلات التالية:
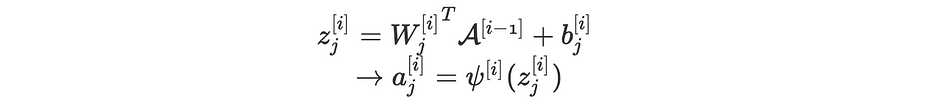
عندما يكون dropout مُفعَّلًا، تصبح المعادلات على النحو التالي:
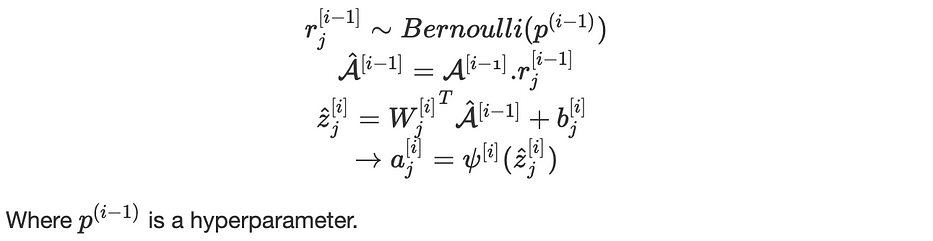
Early stopping
هذه التقنية بسيطة جدًّا وتتمثّل في إيقاف التكرار حول المنطقة التي يبدأ فيها J_train وJ_dev في الافتراق:
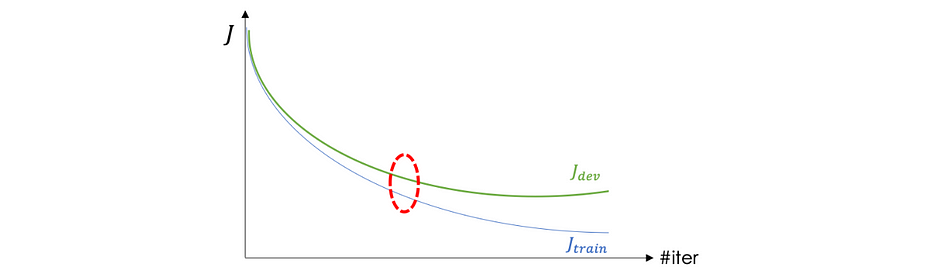
مشاكل Gradient
يُعاني حساب gradients من مشكلتَين رئيسيتَين: gradient vanishing وgradient exploding.
لتوضيح كلتا الحالتَين، لننظر في شبكة عصبية حيث جميع دوال التنشيط ψ[i] خطّية و:
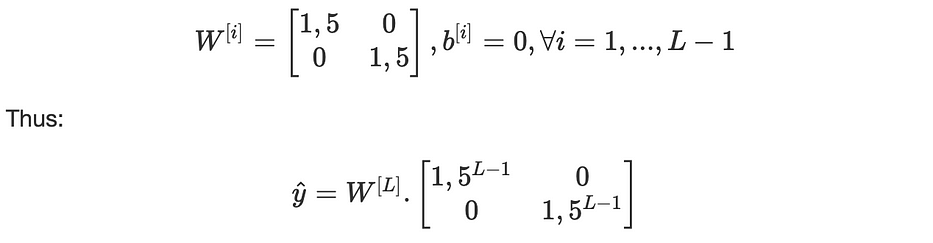
نُلاحظ أنّ 1,5^(L−1) سينفجر أُسّيًا كدالّة للعمق L. إذا استخدمنا 0.5 بدلًا من 1,5 فإنّ 0,5^(L-1) ستتلاشى أُسّيًا أيضًا.
تحدث المشكلة نفسها مع gradients.
الخاتمة
بصفتك Data Scientist، من المهمّ جدًّا أن تكون على دراية بالرياضيات التي تدور في الخلفية للشبكات العصبية. هذا يُتيح فهمًا أفضل وتصحيحًا أسرع للأخطاء.
لا تتردّد في الاطلاع على مقالاتي السابقة التي تناقش:
- Convolutional Neural Networks’ mathematics
- Object detection & Face recognition algorithms
- Recurrent Neural Networks
Happy Machine Learning!
المراجع
- Deep Learning Specialization, Coursera, Andrew Ng
- Optimization course, Mines Nancy, Antoine Henrot
- Machine Learning, Loria, Christophe Cerisara