
PDF files or Portable Document Format are a type of files developed by Adobe in order to enable the creation of various forms of content. Particularly, it allows consistent safety regarding the change in its content. A PDF file can host different types of data: text, images, media, …etc. It is a tag-structured file which makes it easy to parse it just like an HTML page.
With that being said and for the sake of structure, we can separate the PDF files into two classes:
- Text-based files: containing text that can be copied and pasted
- Image-based files: contained images such as scanned documents
In this article, we will go through the main python libraries which enable PDF files parsing both text-based and image-based ones which will be OCRised and then processed as a text-based file. We will also cover in the last chapter how to use the object detection algorithm YOLOV3 in order to parse tables.
The summary is as follows:
- Image-based pdf files
1.1. OCRMYPDF - Text-based pdf files
2.1. PyPDF2
2.2. PDF2IMG
2.4. Camelot
2.5. Camelot mixed with YOLOV3
For the sake of illustration all along with this article, we will use this pdf file.
Image-based pdf files
1. OCRMYPDF
Ocrmypdf is a python package which allow to turn an image-based pdf into a text-based one, where text can be selected, copied and pasted.
In order to install ocrmypdf you can use brew for macOS and Linux using the command line:
brew install ocrmypdfOnce the package is installed, you can ocrise your pdf file by running the following command line:
ocrmypdf input_file.pdf output_file.pdfwhere:
- ocrmypdf: the path variable
- input_file.pdf: the image-based pdf file
- output_file.pdf: the output text-based file
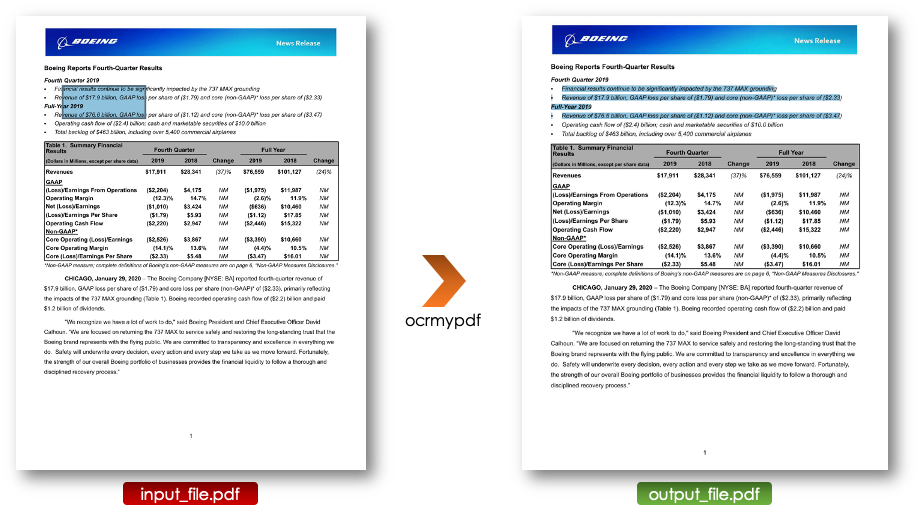
Once the pdf is turned into a text-based one, it can be treated using all the libraries detailed below.
For further details on ocrmypdf, please visit the following the official website.
Text-based pdf files
In this section, we will mainly focus on three python libraries that allow to extract the content of a text-based pdf file.
1. PyPDF2
PyPDF2 is a python tool which enables us to parse basic information about the pdf file such the author the title…etc. It also allows the get the text of a given page along with splitting pages and opening encrypted files under the assumption of having the password.
PyPDF2 can be installed used pip by running the following command line:
pip install PyPDF2We sum all the functionalities listed above the following python scripts:
- Reading a pdf file:
from PyPDF2 import PdfFileWriter, PdfFileReader
PDF_PATH = "boeing.pdf"
pdf_doc = PdfFileReader(open(PDF_PATH, "rb"))- Extracting document information:
print("---------------PDF's info---------------")
print(pdf_doc.documentInfo)
print("PDF is encrypted: " + str(pdf_doc.isEncrypted))
print("---------------Number of pages---------------")
print(pdf_doc.numPages)
>> ---------------PDF's info---------------
>> {'/Producer': 'WebFilings', '/Title': '2019 12 Dec 31 8K Press Release Exhibit 99.1', '/CreationDate': 'D:202001281616'}
>> PDF is encrypted: False
>> ---------------Number of pages---------------
>> 14- Splitting documents page by page:
#indexation starts at 0
pdf_page_1 = pdf_doc.getPage(0)
pdf_page_4 = pdf_doc.getPage(3)
print(pdf_page_1)
print(pdf_page_4)
>> {'/Type': '/Page', '/Parent': IndirectObject(1, 0), '/MediaBox': [0, 0, 612, 792], '/Resources': IndirectObject(2, 0), '/Rotate': 0, '/Contents': IndirectObject(4, 0)}
>> {'/Type': '/Page', '/Parent': IndirectObject(1, 0), '/MediaBox': [0, 0, 612, 792], '/Resources': IndirectObject(2, 0), '/Rotate': 0, '/Contents': IndirectObject(10, 0)}
- Extracting text from a page:
text = pdf_page_1.extractText()
print(text[:500])
>> '1Boeing Reports Fourth-Quarter ResultsFourth Quarter 2019 Financial results continue to be significantly impacted by the 737 MAX grounding Revenue of $17.9 billion, GAAP loss per share of ($1.79) and core (non-GAAP)* loss per share of ($2.33) Full-Year 2019 Revenue of $76.6€billion, GAAP loss per share of ($1.12) and core (non-GAAP)* loss per share of ($3.47) Operating cash flow of ($2.4)€billion; cash and marketable securities of $10.0 billion Total backlog of $463 billion, including over 5,400'- Merging documents page by page:
new_pdf = PdfFileWriter()
new_pdf.addPage(pdf_page_1)
new_pdf.addPage(pdf_page_4)
new_pdf.write(open("new_pdf.pdf", "wb"))
print(new_pdf)
>> <PyPDF2.pdf.PdfFileWriter object at 0x11e23cb10>- Cropping pages:
print("Upper Left: ", pdf_page_1.cropBox.getUpperLeft())
print("Lower Right: ", pdf_page_1.cropBox.getLowerRight())
x1, y1 = 0, 550
x2, y2 = 612, 320
cropped_page = pdf_page_1
cropped_page.cropBox.upperLeft = (x1, y1)
cropped_page.cropBox.lowerRight = (x2, y2)
cropped_pdf = PdfFileWriter()
cropped_pdf.addPage(cropped_page)
cropped_pdf.write(open("cropped.pdf", "wb"))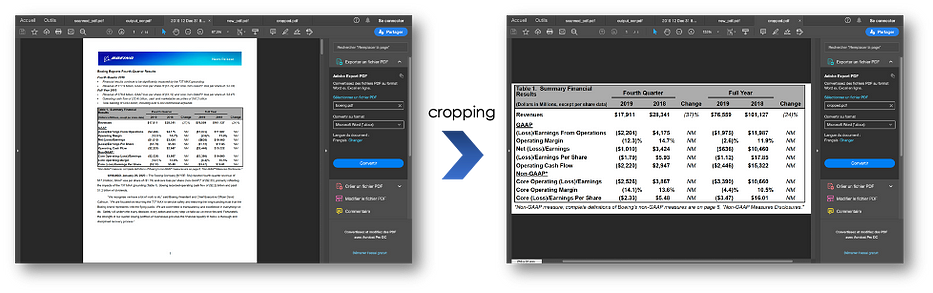
- Encrypting and decrypting PDF files:
PASSWORD = "password_123"encrypted_pdf = PdfFileWriter()encrypted_pdf.addPage(pdf_page_1)encrypted_pdf.encrypt(PASSWORD)encrypted_pdf.write(open("encrypted_pdf.pdf", "wb"))read_encrypted_pdf = PdfFileReader(open("encrypted_pdf.pdf", "rb"))print(read_encrypted_pdf.isEncrypted)if read_encrypted_pdf.isEncrypted: read_encrypted_pdf.decrypt(PASSWORD)print(read_encrypted_pdf.documentInfo)>> True>> {'/Producer': 'PyPDF2'}
For further information on PyPDF2, please visit the official website.
2. PDF2IMG
PDF2IMG is a python library that allows turning pdf pages into images that can be processed, for instance, by computer vision algorithms.
PDF2IMG can be installed using pip by running the following command line:
pip install pdf2imageWe can set the first page and the last page to be transformed to images from the pdf file.
from pdf2image import convert_from_path
import matplotlib.pyplot as plt
page=0
img_page = convert_from_path(PDF_PATH, first_page=page, last_page=page+1, output_folder="./", fmt="jpg")
print(img_page)
>> <PIL.PpmImagePlugin.PpmImageFile image mode=RGB size=1700x2200 at 0x11DF397D0>
3. Camelot
Camelot is a python library specialized in parsing tables of pdfs pages. It can be installed using pip by running the following command line:
pip install camelot-py[cv]The output of the parsing is a pandas dataframe which is very useful for data processing.
import camelot
output_camelot = camelot.read_pdf(
filepath="output_ocr.pdf", pages=str(0), flavor="stream"
)
print(output_camelot)
table = output_camelot[0]
print(table)
print(table.parsing_report)
>> TableList n=1>
>> <Table shape=(18, 8)>
>> {'accuracy': 93.06, 'whitespace': 40.28, 'order': 1, 'page': 0}When the pdf page contains text, the output of Camelot will be a data frame containing text in the first columns and later the desired table. With some basic processing we can extract it as follows:
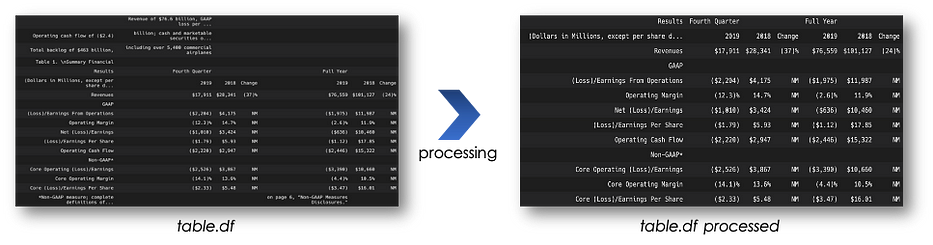
Camelot offers two flavors lattice and stream, I advise to use stream since it is more flexible to tables structure.
4. Camelot mixed with YOLOV3
Camelot offers the option of specifying the regions to process through the variable table_areas="x1,y1,x2,y2" where (x1, y1) is left-top and (x2, y2) right-bottom in PDF coordinate space. When filled out, the result of the parsing is significantly enhanced.
Explaining the basic idea
One way to automize the parsing of tables is to train an algorithm capable of returning the coordinates of the bounding boxes circling the tables, as detailed in the following pipeline:

If the primitive pdf page is image-based, we can use ocrmypdf to turn into a text-based one in order to be able to get the text inside the table. We, then, carry out the following operations:
- Transform a pdf page into an image one using
pdf2img - Use a trained algorithm to detect the regions of tables.
- Normalize the bounding boxes, using the image dimension, which enables to get the regions in the pdf space using the pdf dimensions obtained through
PyPDF2. - Feed the regions to
camelotand get the corresponding pandas data-frames.
When detecting a table in pdf image we expand the bounding box in order to guarantee its full inclusion, as follows:
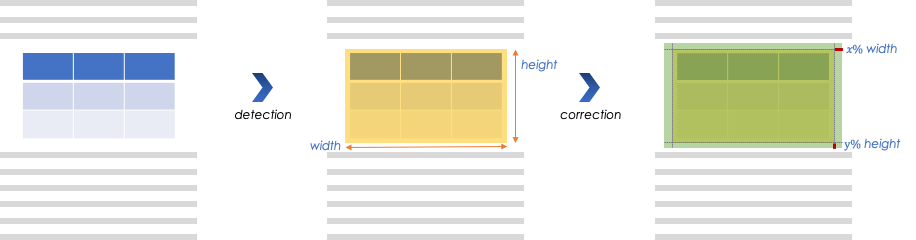
Tables detection
The algorithm which allows the detection of tables is nothing but yolov3, I advise you to read my previous article about objects detection.
We finetune the algorithm to detect tables and retrain all the architecture. To do so, we carry out the following steps:
- Create a training database using
Makesensea tool which enables labeling and exporting in YOLO’s format:
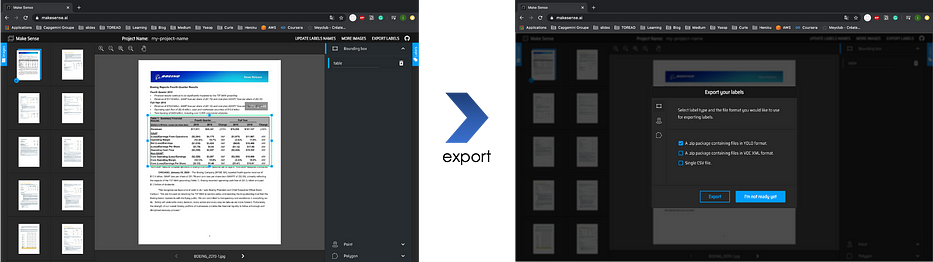
- Train a
yolov3repositorymodified to fit our purpose on AWS EC2, we get the following results:
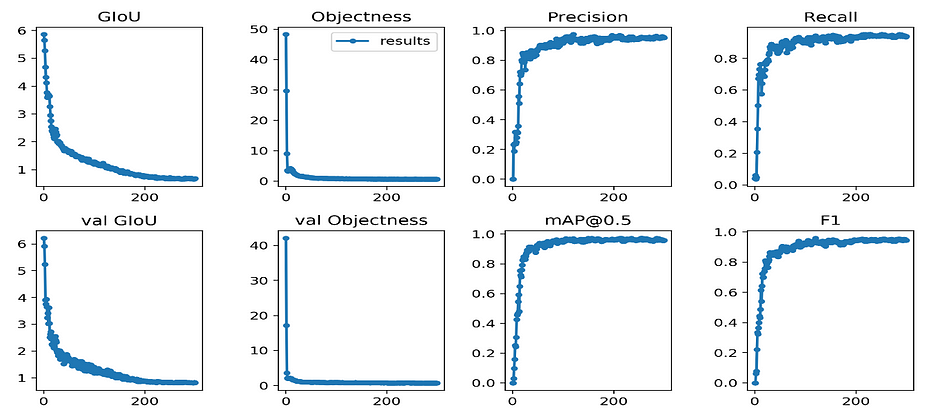
Illustration
The detections look as follows:

Conclusion
When mixing standard python libraries with deep learning algorithm it is possible to significantly enhance the parsing of PDF documents. Matter of fact, following the same steps, we can train YOLOV3 algorithm to detect any other object in a pdf page such as graphics and images which can be extracted from the image page.
You can check my project in my GitHub.
Do not hesitate to check my previous articles dealing with:
- Deep Learning’s mathematics
- Convolutional Neural Networks’ mathematics
- Object detection & Face recognition algorithms
- Recurrent Neural Networks